mirror of
https://github.com/Steffo99/unisteffo.git
synced 2025-02-18 16:43:58 +00:00
Add algoritmi and prog2
This commit is contained in:
parent
182eaceea0
commit
da0494d385
51 changed files with 2365 additions and 20 deletions
|
|
@ -1,11 +1,29 @@
|
|||
import { Panel } from "@steffo/bluelib-react"
|
||||
import { Panel, BringAttention as B } from "@steffo/bluelib-react"
|
||||
|
||||
export const Warning = (props) => {
|
||||
|
||||
export const WarningUnchecked = () => {
|
||||
return (
|
||||
<Panel builtinColor="yellow">
|
||||
|
||||
<B>Attenzione:</B> questi file non sono stati ricontrollati da quando sono stati scritti, e potrebbero contenere errori!<br/>
|
||||
<B>⚠️ Attenzione:</B> questi materiali non sono stati ricontrollati da quando sono stati scritti, e potrebbero contenere errori!<br/>
|
||||
<small>Usali a tuo rischio e pericolo!</small>
|
||||
</Panel>
|
||||
)
|
||||
}
|
||||
|
||||
export const WarningIncomplete = () => {
|
||||
return (
|
||||
<Panel builtinColor="yellow">
|
||||
<B>⚠️ Attenzione:</B> questi materiali non coprono tutto il programma, e non sono quindi sufficienti per dare l'esame!<br/>
|
||||
<small>Usali per ripassare quello che hai studiato.</small>
|
||||
</Panel>
|
||||
)
|
||||
}
|
||||
|
||||
export const WarningBlocked = () => {
|
||||
return (
|
||||
<Panel builtinColor="red">
|
||||
<B>🚫 Blocco:</B> questi materiali sono stati resi bloccati per via di fattori esterni a questo sito, e non possono essere ri-aggiunti.<br/>
|
||||
<small>Lamentati con chi li ha bloccati, non con me, non posso farci niente...</small>
|
||||
</Panel>
|
||||
)
|
||||
}
|
||||
|
|
|
|||
|
|
@ -1,7 +1,7 @@
|
|||
import "../styles/global.css"
|
||||
import type { AppProps } from 'next/app'
|
||||
import Link from "next/link"
|
||||
import {Bluelib, Heading, LayoutThreeCol, Anchor as A} from "@steffo/bluelib-react"
|
||||
import {Bluelib, Heading, LayoutThreeCol, Anchor as A, Footer} from "@steffo/bluelib-react"
|
||||
|
||||
function MyApp({ Component, pageProps }: AppProps) {
|
||||
return (
|
||||
|
|
@ -16,6 +16,17 @@ function MyApp({ Component, pageProps }: AppProps) {
|
|||
<Component {...pageProps} />
|
||||
</LayoutThreeCol.Center>
|
||||
</LayoutThreeCol>
|
||||
<Footer>
|
||||
<p>
|
||||
© {new Date().getFullYear()} <A href="https://steffo.eu/">Stefano Pigozzi</A> - Tutto il contenuto del sito è reso disponibile con la licenza <A href="https://creativecommons.org/licenses/by-sa/3.0/it/">CC-BY-SA 3.0 IT</A>.
|
||||
</p>
|
||||
<p>
|
||||
Sito web <A href="https://github.com/Steffo99/appuntiweb-omega">open source</A> basato su <A href="https://github.com/Steffo99/bluelib">Bluelib</A> e <A href="https://github.com/Steffo99/bluelib-react">Bluelib React</A>
|
||||
</p>
|
||||
<p>
|
||||
Se il contenuto di questo sito ti è utile, <A href="https://ko-fi.com/steffo">offrimi un caffè</A>!
|
||||
</p>
|
||||
</Footer>
|
||||
</Bluelib>
|
||||
)
|
||||
}
|
||||
|
|
|
|||
|
|
@ -50,12 +50,12 @@ const Home: NextPage = () => {
|
|||
</ListUnordered.Item>
|
||||
<ListUnordered.Item>
|
||||
<Link href="/year1/algoritmi">
|
||||
<A>Algoritmi e strutture dati</A>
|
||||
<A href="#">Algoritmi e strutture dati</A>
|
||||
</Link>
|
||||
</ListUnordered.Item>
|
||||
<ListUnordered.Item>
|
||||
<Link href="/year1/programmazione2">
|
||||
<A>Programmazione 2</A>
|
||||
<A href="#">Programmazione 2</A>
|
||||
</Link>
|
||||
</ListUnordered.Item>
|
||||
</ListUnordered>
|
||||
|
|
|
|||
|
|
@ -1,5 +1,6 @@
|
|||
import { Heading, Chapter, Box, Idiomatic as I, Code, Anchor as A, Dialog, BringAttention as B, ListOrdered, ListUnordered} from '@steffo/bluelib-react'
|
||||
import type { NextPage } from 'next'
|
||||
import { WarningBlocked } from '../../components/warnings'
|
||||
|
||||
const Page: NextPage = () => {
|
||||
return <>
|
||||
|
|
@ -27,10 +28,7 @@ const Page: NextPage = () => {
|
|||
<Heading level={3}>
|
||||
Videolezioni usate
|
||||
</Heading>
|
||||
<Dialog builtinColor='blue'>
|
||||
<B>Gennaio 2022:</B> Come sempre, Unimore ha fatto del suo meglio per ostacolare lo studio ai suoi studenti, e quindi ha reso tutte le videolezioni su YouTube private.<br/>
|
||||
<small>Quelle su Vimeo ci sono ancora, però...</small>
|
||||
</Dialog>
|
||||
<WarningBlocked/>
|
||||
<ListOrdered>
|
||||
<ListOrdered.Item>
|
||||
<A>Definizione di Spazio Vettoriale</A> (1:17:29)
|
||||
|
|
|
|||
167
pages/year1/algoritmi.tsx
Normal file
167
pages/year1/algoritmi.tsx
Normal file
|
|
@ -0,0 +1,167 @@
|
|||
import { Heading, Chapter, Box, Idiomatic as I, Code, Anchor as A, Dialog, BringAttention as B, ListOrdered, ListUnordered } from "@steffo/bluelib-react"
|
||||
import type { NextPage } from "next"
|
||||
import { WarningUnchecked } from "../../components/warnings"
|
||||
|
||||
|
||||
const MaterialLi = ({children, file}) => {
|
||||
return <ListOrdered.Item>
|
||||
{children} (<A href={`/materials/year1/algoritmi/${file}.md`}><Code>.md</Code></A>)
|
||||
</ListOrdered.Item>
|
||||
}
|
||||
|
||||
|
||||
const Page: NextPage = () => {
|
||||
return <>
|
||||
<Heading level={2}>
|
||||
Algoritmi e strutture dati
|
||||
</Heading>
|
||||
<Chapter>
|
||||
<Box>
|
||||
<Heading level={3}>
|
||||
Introduzione
|
||||
</Heading>
|
||||
<p>
|
||||
Il corso di <I>Algoritmi e strutture dati</I> è stato piuttosto impegnativo ma al tempo stesso interessante: quasi tutto il materiale era composto da concetti a me nuovi, e di conseguenza ho preso appunti dettagliati su tutto.
|
||||
</p>
|
||||
</Box>
|
||||
</Chapter>
|
||||
<Chapter>
|
||||
<Box>
|
||||
<Heading level={3}>
|
||||
Materiale realizzato
|
||||
</Heading>
|
||||
<WarningUnchecked/>
|
||||
<ListOrdered>
|
||||
<MaterialLi file="01_IlNomeDelCorso.md">
|
||||
Il nome del corso
|
||||
</MaterialLi>
|
||||
<MaterialLi file="02_EfficienzaDegliAlgoritmi.md">
|
||||
Efficienza degli algoritmi
|
||||
</MaterialLi>
|
||||
<MaterialLi file="03_ModelliAlgoritmici.md">
|
||||
Modelli algoritmici
|
||||
</MaterialLi>
|
||||
<MaterialLi file="04_NotazioneAsintotica.md">
|
||||
Notazione asintotica
|
||||
</MaterialLi>
|
||||
<MaterialLi file="05_ProblemiAlgoritmici.md">
|
||||
Problemi algoritmici
|
||||
</MaterialLi>
|
||||
<MaterialLi file="06_RicercaBinaria.md">
|
||||
Ricerca binaria
|
||||
</MaterialLi>
|
||||
<MaterialLi file="07_DivideEtImpera.md">
|
||||
Divide et impera
|
||||
</MaterialLi>
|
||||
<MaterialLi file="08_MasterTheorem.md">
|
||||
Master theorem
|
||||
</MaterialLi>
|
||||
<MaterialLi file="09_MasterTheoremSubset.md">
|
||||
Master theorem subset
|
||||
</MaterialLi>
|
||||
<MaterialLi file="10_Ordinamento.md">
|
||||
Ordinamento
|
||||
</MaterialLi>
|
||||
<MaterialLi file="11_InsertionSort.md">
|
||||
Insertion sort
|
||||
</MaterialLi>
|
||||
<MaterialLi file="11_MergeSort.md">
|
||||
Merge sort
|
||||
</MaterialLi>
|
||||
<MaterialLi file="11_QuickSort.md">
|
||||
Quick sort
|
||||
</MaterialLi>
|
||||
<MaterialLi file="12_CountingSort.md">
|
||||
Counting sort
|
||||
</MaterialLi>
|
||||
<MaterialLi file="13_IntroAlleStruttureDati.md">
|
||||
Introduzione alle strutture dati
|
||||
</MaterialLi>
|
||||
<MaterialLi file="14_Array.md">
|
||||
Array
|
||||
</MaterialLi>
|
||||
<MaterialLi file="14_Lista.md">
|
||||
Lista
|
||||
</MaterialLi>
|
||||
<MaterialLi file="15_Coda.md">
|
||||
Coda
|
||||
</MaterialLi>
|
||||
<MaterialLi file="15_Pila.md">
|
||||
Pila
|
||||
</MaterialLi>
|
||||
<MaterialLi file="16_AlberoRadicato.md">
|
||||
Albero radicato
|
||||
</MaterialLi>
|
||||
<MaterialLi file="17_BreadthFirstSearch.md">
|
||||
Breadth-first search
|
||||
</MaterialLi>
|
||||
<MaterialLi file="17_DepthFirstSearch.md">
|
||||
Depth-first search
|
||||
</MaterialLi>
|
||||
<MaterialLi file="18_AlberoBinarioDiRicerca.md">
|
||||
Albero binario di ricerca
|
||||
</MaterialLi>
|
||||
<MaterialLi file="19_HeapBinario.md">
|
||||
Heap binario
|
||||
</MaterialLi>
|
||||
<MaterialLi file="20_CodaConPriorità.md">
|
||||
Coda con priorità
|
||||
</MaterialLi>
|
||||
<MaterialLi file="20_HeapSort.md">
|
||||
Heap sort
|
||||
</MaterialLi>
|
||||
<MaterialLi file="21_Grafo.md">
|
||||
Grafo
|
||||
</MaterialLi>
|
||||
<MaterialLi file="22_VisitareUnGrafo.md">
|
||||
Visitare un grafo
|
||||
</MaterialLi>
|
||||
<MaterialLi file="23_AlgoritmiGreedy.md">
|
||||
Algoritmi greedy
|
||||
</MaterialLi>
|
||||
<MaterialLi file="24_PercorsoPiùBreve.md">
|
||||
Percorso più breve
|
||||
</MaterialLi>
|
||||
<MaterialLi file="25_AlgoritmoDiDijkstra.md">
|
||||
Algoritmo di Dijkstra
|
||||
</MaterialLi>
|
||||
<MaterialLi file="26_AlgoritmoDiBellmanFord.md">
|
||||
Algoritmo di Bellman-Ford
|
||||
</MaterialLi>
|
||||
<MaterialLi file="27_DisjointSet.md">
|
||||
Disjoint set
|
||||
</MaterialLi>
|
||||
<MaterialLi file="28_TrovareIlMST.md">
|
||||
Trovare il minimum spanning tree
|
||||
</MaterialLi>
|
||||
<MaterialLi file="29_AlgoritmoDiKruskal.md">
|
||||
Algoritmo di Kruskal
|
||||
</MaterialLi>
|
||||
<MaterialLi file="29_AlgoritmoDiPrim.md">
|
||||
Algoritmo di Prim
|
||||
</MaterialLi>
|
||||
<MaterialLi file="30_Compressione.md">
|
||||
Compressione
|
||||
</MaterialLi>
|
||||
<MaterialLi file="31_AlgoritmoDiHuffman.md">
|
||||
Algoritmo di Huffman
|
||||
</MaterialLi>
|
||||
<MaterialLi file="32_Dizionari.md">
|
||||
Dizionari
|
||||
</MaterialLi>
|
||||
<MaterialLi file="33_ProgrammazioneDinamica.md">
|
||||
Programmazione dinamica
|
||||
</MaterialLi>
|
||||
<MaterialLi file="34_ProblemaDelloZaino.md">
|
||||
Problema dello zaino
|
||||
</MaterialLi>
|
||||
<MaterialLi file="35_ProblemiIntrattabili.md">
|
||||
Problemi intrattabili
|
||||
</MaterialLi>
|
||||
</ListOrdered>
|
||||
</Box>
|
||||
</Chapter>
|
||||
</>
|
||||
}
|
||||
|
||||
export default Page
|
||||
|
|
@ -1,5 +1,6 @@
|
|||
import { Heading, Chapter, Box, Idiomatic as I, Code, Anchor as A, Dialog, BringAttention as B, ListOrdered, ListUnordered} from '@steffo/bluelib-react'
|
||||
import type { NextPage } from 'next'
|
||||
import { WarningIncomplete, WarningUnchecked } from "../../components/warnings"
|
||||
|
||||
const MaterialLi = ({children, file}) => {
|
||||
return <ListOrdered.Item>
|
||||
|
|
@ -35,6 +36,8 @@ const Page: NextPage = () => {
|
|||
<Heading level={3}>
|
||||
Materiale realizzato
|
||||
</Heading>
|
||||
<WarningUnchecked/>
|
||||
<WarningIncomplete/>
|
||||
<p>
|
||||
Ho cercato di riordinare gli appunti in base a come ricordo fosse ordinato il programma. Spero di non essermi sbagliato!
|
||||
</p>
|
||||
|
|
@ -90,14 +93,6 @@ const Page: NextPage = () => {
|
|||
Successioni (<A href={`/materials/year1/analisi/X_successioni.md`}><Code>.md</Code></A>)
|
||||
</ListUnordered.Item>
|
||||
</ListUnordered>
|
||||
<Dialog builtinColor='yellow'>
|
||||
<B>Attenzione:</B> questi file non sono stati ricontrollati da quando sono stati scritti, e potrebbero contenere errori!<br/>
|
||||
<small>Usali a tuo rischio e pericolo!</small>
|
||||
</Dialog>
|
||||
<Dialog builtinColor='yellow'>
|
||||
<B>Attenzione:</B> questi file sono incompleti, e non sono quindi sufficienti per dare l'esame!<br/>
|
||||
<small>Studia sul materiale, e poi usa questi per verificare quello che hai studiato.</small>
|
||||
</Dialog>
|
||||
</Box>
|
||||
</Chapter>
|
||||
</>
|
||||
|
|
|
|||
|
|
@ -1,6 +1,7 @@
|
|||
import { Heading, Chapter, Box, Idiomatic as I, Anchor as A, UAnnotation as U, ListUnordered, BringAttention as B, ListOrdered, Definition, Code } from '@steffo/bluelib-react'
|
||||
import type { NextPage } from 'next'
|
||||
import Head from 'next/head'
|
||||
import { WarningIncomplete, WarningUnchecked } from '../../components/warnings'
|
||||
|
||||
|
||||
const MaterialLi = ({children, file}) => {
|
||||
|
|
@ -33,6 +34,8 @@ const Page: NextPage = () => {
|
|||
<Heading level={3}>
|
||||
Materiale realizzato
|
||||
</Heading>
|
||||
<WarningIncomplete/>
|
||||
<WarningUnchecked/>
|
||||
<p>
|
||||
Ho glissato molto sulla parte teorica, in quanto le dispense forniteci dal prof. erano ottime.
|
||||
</p>
|
||||
|
|
|
|||
|
|
@ -1,5 +1,6 @@
|
|||
import { Heading, Chapter, Box, Idiomatic as I, Code, Anchor as A, Dialog, BringAttention as B, ListOrdered, ListUnordered } from "@steffo/bluelib-react"
|
||||
import type { NextPage } from "next"
|
||||
import { WarningUnchecked } from "../../components/warnings"
|
||||
|
||||
import Image from "next/image"
|
||||
import imgmDZSqjV from "../../public/images/year1/programmazione1/mDZSqjV.png"
|
||||
|
|
@ -55,6 +56,7 @@ const Page: NextPage = () => {
|
|||
<Heading level={3}>
|
||||
Come installare correttamente MinGW su Windows
|
||||
</Heading>
|
||||
<WarningUnchecked/>
|
||||
<p>
|
||||
Scaricate <A href="https://osdn.net/projects/mingw/downloads/68260/mingw-get-setup.exe/">l'installer ufficiale</A>, ed eseguitelo.
|
||||
</p>
|
||||
|
|
|
|||
31
pages/year1/programmazione2.tsx
Normal file
31
pages/year1/programmazione2.tsx
Normal file
|
|
@ -0,0 +1,31 @@
|
|||
import { Heading, Chapter, Box, Idiomatic as I, Anchor as A, ListUnordered, ListOrdered, BringAttention as B } from '@steffo/bluelib-react'
|
||||
import type { NextPage } from 'next'
|
||||
|
||||
const Page: NextPage = () => {
|
||||
return <>
|
||||
<Heading level={2}>
|
||||
Programmazione 2
|
||||
</Heading>
|
||||
<Chapter>
|
||||
<Box>
|
||||
<Heading level={3}>
|
||||
Introduzione
|
||||
</Heading>
|
||||
<p>
|
||||
<I>Programmazione 2</I>... è stato terrificante.
|
||||
</p>
|
||||
<p>
|
||||
Il programma non aveva il minimo senso: insegnava praticamente come <B>NON PROGRAMMARE</B> in C++; le <I>worst practices</I>, se vogliamo.
|
||||
</p>
|
||||
<p>
|
||||
Se non è cambiato da allora, e dovete darlo... Vi consiglio di trovare un bel libro di C++ di base, studiarvelo da soli, e solo dopo che avete capito più o meno tutti i concetti principali tuffarvi nel mare di assurdità che sono le slides del corso.
|
||||
</p>
|
||||
<p>
|
||||
Purtroppo non conosco buoni libri di C++, quindi dovete trovarvelo da soli, ma sono sicuro che ne esistano centinaia!
|
||||
</p>
|
||||
</Box>
|
||||
</Chapter>
|
||||
</>
|
||||
}
|
||||
|
||||
export default Page
|
||||
43
public/materials/year1/algoritmi/01_IlNomeDelCorso.md
Normal file
43
public/materials/year1/algoritmi/01_IlNomeDelCorso.md
Normal file
|
|
@ -0,0 +1,43 @@
|
|||
# Il nome del corso
|
||||
|
||||
## Cosa sono gli algoritmi?
|
||||
|
||||
Gli algoritmi sono modi sistematici per risolvere problemi.
|
||||
|
||||
Sono fondamentali per sviluppare software, in quanto i computer sono eccellenti esecutori di algoritmi.
|
||||
|
||||
## Come si sviluppa un algoritmo?
|
||||
|
||||
Innanzitutto, bisogna conoscere gli _input_ e gli _output_ del problema, rispettivamente i dati di partenza e i dati di arrivo di esso; si ha quindi una fase di **ricerca**.
|
||||
|
||||
Poi, si deve trovare un procedimento che ci faccia risolvere il nostro problema: è quello che faremo in questa materia!
|
||||
|
||||
Infine, bisogna scrivere la soluzione in un modo che possa essere eseguita da un computer: questa è la **programmazione**.
|
||||
|
||||
## Che tipo di problemi possiamo risolvere?
|
||||
|
||||
Un algoritmo risolve problemi di tipo generale, non ci interessa sapere _il risultato di 123+456_, ma vogliamo sapere _il risultato di x+y_, dove x e y sono due numeri naturali qualsiasi.
|
||||
|
||||
Un problema può essere quindi considerato circa come una **funzione matematica**, che connette ogni input a un output corrispondente.
|
||||
|
||||
## Che caratteristiche ha un algoritmo?
|
||||
|
||||
Per prima cosa, ripetendo l'algoritmo più volte con lo stesso ingresso deve dare sempre la stessa uscita come **risultato**, finendo in un **tempo finito**.
|
||||
|
||||
Deve essere **ben ordinato**: cambiando l'ordine in cui vengono effettuate le operazioni, è probabile che anche il risultato cambi!
|
||||
|
||||
Le sue istruzioni devono essere **non ambigue**, cioè che non possano essere interpretate in più modi, e **effettivamente realizzabili**, cioè realizzabili con l'esecutore che vogliamo usare per eseguire l'algoritmo.
|
||||
|
||||
## Esistono algoritmi equivalenti?
|
||||
|
||||
**Sì!** Possono esserci due algoritmi che dati gli stessi input, hanno gli stessi output, e quindi risolvono lo stesso problema.
|
||||
|
||||
In compenso, possono avere un numero di operazioni diverse, e quindi essere **uno più veloce** (da eseguire) dell'altro.
|
||||
|
||||
## Come si verifica la correttezza di un algoritmo?
|
||||
|
||||
L'algoritmo deve essere **valido per tutti gli input**, anche se questi sono infiniti.
|
||||
|
||||
Possiamo effettuare prove matematiche per verificarne la correttezza; il **principio di induzione** è dunque una dei teoremi fondamentali dell'algoritmica.
|
||||
|
||||
Possiamo però verificare la _non correttezza_ di un algoritmo trovando un singolo controesempio.
|
||||
|
|
@ -0,0 +1,42 @@
|
|||
# Efficienza degli algoritmi
|
||||
|
||||
Un buon algoritmo deve essere **efficiente**, ovvero deve usare il minimo delle risorse necessarie, come _usare il minimo di tempo possibile_.
|
||||
|
||||
## Come misuriamo il tempo necessario?
|
||||
|
||||
Cerchiamo di astrarre il tempo dal particolare esecutore, e andiamo a contare il numero di operazioni elementari richieste per eseguire il nostro algoritmo nel caso peggiore.
|
||||
|
||||
Un algoritmo efficiente, infatti, all'aumentare dei dati in ingresso, diventerà sempre più veloce rispetto a uno non efficiente, anche su computer più lenti!
|
||||
|
||||
> Il [Bubble Sort](https://en.wikipedia.org/wiki/Bubble_sort) è sempre più lento di un [Tree Sort](https://en.wikipedia.org/wiki/Tree_sort), anche su computer più lenti, perchè, dovendo ordinare liste sempre più lunghe, prima o poi si raggiunge un punto in cui il primo è più veloce (in termini di tempo) dell'altro.
|
||||
|
||||
Dobbiamo andare a vedere, quindi, _il numero di operazioni richieste per ottenere il risultato nel caso peggiore_.
|
||||
|
||||
Consideriamo operazioni sia operazioni aritmetiche sia operazioni logiche, e diciamo che ciascuna costa 1.
|
||||
|
||||
> L'[algoritmo di Euclide](https://it.wikipedia.org/wiki/Algoritmo_di_Euclide) per l'MCD costa `3` per ogni iterazione (un giro del ciclo `while`). Diciamo, allora, che costa `3n`, dove `n` è il numero più alto dei due, perchè nel caso peggiore (uno dei due numeri è 1) l'algoritmo compie `n` iterazioni.
|
||||
|
||||
## Altri parametri ottimizzabili
|
||||
|
||||
È possibile che alcuni algoritmi per vari motivi cerchino di ottimizzare altri parametri diversi dal tempo, come ad esempio _la dimensione dell'input_ o la _memoria utilizzata_.
|
||||
|
||||
> Generalmente, questo viene fatto sui dispositivi embedded, con memoria molto limitata.
|
||||
|
||||
### Criteri di costo di memoria
|
||||
|
||||
Ci sono vari criteri con cui stimare la memoria richiesta da un dato: è possibile che il costo risultante vari in base al criterio scelto!
|
||||
|
||||
#### Criterio di costo logaritmico
|
||||
|
||||
Un dato costa il numero di bit necessari per rappresentarlo.
|
||||
|
||||
> Un int che contiene il numero `n` costa `log_2(n)`.
|
||||
> Un array di `[n]` numeri tutti uguali costa `n log_2(n)`.
|
||||
|
||||
#### Criterio di costo uniforme
|
||||
|
||||
Un dato costa il numero di elementi che lo costituiscono.
|
||||
|
||||
> Un int che contiene il numero `n` costa `1`.
|
||||
> Un array di `[n]` numeri costa `n`.
|
||||
> Una matrice `[m][n]` costa `m*n`.
|
||||
14
public/materials/year1/algoritmi/03_ModelliAlgoritmici.md
Normal file
14
public/materials/year1/algoritmi/03_ModelliAlgoritmici.md
Normal file
|
|
@ -0,0 +1,14 @@
|
|||
# Modelli algoritmici
|
||||
|
||||
Per progettare un algoritmo, abbiamo bisogno di sapere le proprietà del nostro esecutore, ovvero il suo _modello algoritmico_.
|
||||
|
||||
> Ad esempio, dobbiamo sapere quali istruzioni è in grado di eseguire, e quanto tempo queste istruzioni richiedono.
|
||||
|
||||
## Il modello RAM
|
||||
|
||||
Il modello in uso su tutti i computer attuali è il _modello RAM_:
|
||||
|
||||
- In ogni cella di memoria può essere archiviato un dato.
|
||||
- Il **tempo di accesso** alle celle è **costante** per tutte le celle.
|
||||
- La **memoria** principale è **infinita**.
|
||||
- Si ha **un solo processore**.
|
||||
135
public/materials/year1/algoritmi/04_NotazioneAsintotica.md
Normal file
135
public/materials/year1/algoritmi/04_NotazioneAsintotica.md
Normal file
|
|
@ -0,0 +1,135 @@
|
|||
# Notazione asintotica
|
||||
|
||||
La _notazione asintotica_ è un sistema per **stimare** velocemente il costo di un algoritmo complesso.
|
||||
|
||||
Ci permette di **confrontare velocemente il caso peggiore** degli algoritmi.
|
||||
|
||||
In particolare, consideriamo il _rapporto tra il numero di operazioni nel caso peggiore e la dimensione dell'input_.
|
||||
|
||||
## Limiti
|
||||
|
||||
Possiamo dare a questa stima dei limiti, superiore e inferiore, che rappresenteranno rispettivamente un costo che non sarà **mai superato** e un costo che verrà **sempre superato**.
|
||||
|
||||
Chiameremo questi limiti _upper bound_ e _lower bound_; la loro combinazione darà un _tight bound_.
|
||||
|
||||
L'obiettivo sarà di _ricavare i bound più precisi possibile_ per un dato algoritmo, ovvero l'**upper bound più basso** e il **lower bound più alto**.
|
||||
|
||||
### O grande
|
||||
|
||||
> "O grande"
|
||||
> O di g(n)
|
||||
> "big-O"
|
||||
|
||||
Per rappresentare la stima, useremo una notazione particolare, detta _O grande_, con la seguente proprietà:
|
||||
- Date due funzioni `f(n) : N -> R` e `g(n) : N -> R`, diremo che `f(n) ∈ O(g(n))` se e soltanto se `∃ c > 0, n ≥ n_0` tali che `∀ n ≥ 0, f(n) ≤ c * g(n)`
|
||||
|
||||
Quando una funzione è O grande di un altra, significa che **asintoticamente, la funzione in O grande è sempre maggiore di quella che sta venendo stimata**.
|
||||
|
||||
> **Ipotesi**
|
||||
> - `f(n) = 2n² + 3n + 6`
|
||||
> - `g(n) = n²`
|
||||
>
|
||||
> **Tesi**
|
||||
> - `f(n) ∈ O(n²)`.
|
||||
>
|
||||
> **Svolgimento**
|
||||
> Scrivo una disequazione, lasciando intatto il termine noto:
|
||||
> 1. `2n² + 3n + 6 ≤ 2n² + 3n² + 6`
|
||||
> 2. `n² ≤ 2n² + 3n² + n² = 6n²` per `n ≥ 3`
|
||||
>
|
||||
> Sappiamo, allora, che `2n² + 3n + 6 ≤ 6n²`.
|
||||
|
||||
#### Espressioni di O grande
|
||||
|
||||
Questa tabella rappresenta le espressioni di O grande più comunemente utilizzate, in ordine **dalla più forte alla più debole**.
|
||||
|
||||
> Più forte significa che, per ogni riga della tabella, tutte le righe sottostanti sono contenute nell'espressione.
|
||||
>
|
||||
> Ad esempio, `O(n) ∈ O(1)`.
|
||||
|
||||
| Espressione O() | Nome |
|
||||
|-----------------|------|
|
||||
| `O(1)` | Costante |
|
||||
| `O(log log n)` | loglog |
|
||||
| `O(log n)` | Logaritmica |
|
||||
| 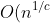) (per c ≥ 1) | Sublineare |
|
||||
| `O(n)` | Lineare |
|
||||
| `O(n log n)` | nlogn |
|
||||
| `O(n²)` | Quadratica |
|
||||
| `O(n³)` | Cubica |
|
||||
| `O(n^k)` (per k ≥ 1) | Polinomiale |
|
||||
| `O(a^n)` (per a ≥ 1) | Esponenziale |
|
||||
| `O(n!)` | Fattoriale |
|
||||
|
||||
#### Polinomiale
|
||||
|
||||
Molto spesso, noteremo che il tempo richiesto da una funzione è O grande di un polinomio di grado K, ovvero `f(n) ∈ O(n^k)`.
|
||||
|
||||
Notiamo che in questi casi, possiamo semplificare l'O grande al grado massimo del polinomio.
|
||||
|
||||
> Ad esempio, `O(n² + n + 1) = O(n²)`.
|
||||
|
||||
##### Dimostrazione
|
||||
|
||||
Per `n > 0 \and 0 ≤ i ≤ k`:
|
||||
%20n^k)
|
||||
|
||||
#### Proprietà di O grande
|
||||
|
||||
1. `f(n) ∈ O(g(n)) -> ∀ a > 0, a * f(n) ∈ O(g(n))`.
|
||||
2. `f(n) ∈ O(g(n)), d(n) ∈ O(h(n)) -> f(n) + d(n) ∈ O(g(n) + h(n)) -> O(max\{g(n), h(n)\})`
|
||||
3. `f(n) ∈ O(g(n)), d(n) ∈ O(h(n)) -> f(n) * d(n) ∈ O(g(n) * h(n))`
|
||||
|
||||
In pratica, se una funzione è la _somma di più termini_, basta guardare l'**`O()` più grande** tra tutti i suoi termini; se invece una funzione è un _prodotto di più termini_, si possono **omettere le costanti**, e l'`O()` finale sarà dato dal **prodotto degli `O()`** dei termini.
|
||||
|
||||
## Lower bound
|
||||
|
||||
Possiamo anche stimare il _lower bound_, il limite inferiore: il **numero minimo di operazioni** che viene effettuato **nel caso migliore** con la **massima dimensione dell'ingresso**.
|
||||
|
||||
### Ω()
|
||||
|
||||
> "Omega"
|
||||
> Omega di g(n)
|
||||
> "big-Omega"
|
||||
|
||||
Esiste un equivalente di O grande per il lower bound: è detto _Omega grande_, o più semplicemente _Omega_, e funziona nello stesso identico modo, solo... al contrario.
|
||||
|
||||
Diremo che `f(n) ∈ Ω(g(n))` se e solo se `∃ c > 0, n_0 ≥ 0 : ∀ n ≥ n_0 f(n) ≥ c * g(n)`.
|
||||
|
||||
#### Espressioni di Ω()
|
||||
|
||||
Anche in questa tabella le espressioni sono **dalla più forte alla più debole**.
|
||||
|
||||
| Espressione Ω() | Nome |
|
||||
|-----------------|------|
|
||||
| `Ω(n!)` | Fattoriale |
|
||||
| `Ω(a^n)` (per a ≥ 1) | Esponenziale |
|
||||
| `Ω(n^k)` (per k ≥ 1) | Polinomiale |
|
||||
| `Ω(n³)` | Cubica |
|
||||
| `Ω(n²)` | Quadratica |
|
||||
| `Ω(n log n)` | nlogn |
|
||||
| `Ω(n)` | Lineare |
|
||||
| 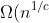) (per c ≥ 1) | Sublineare |
|
||||
| `Ω(log n)` | Logaritmica |
|
||||
| `Ω(log log n)` | loglog |
|
||||
| `Ω(1)` | Costante |
|
||||
|
||||
## Tight bound
|
||||
|
||||
Quando **upper e lower bound coincidono**, allora otteniamo un _tight bound_.
|
||||
|
||||
### θ()
|
||||
|
||||
> "Theta"
|
||||
> Theta di g(n)
|
||||
> "big-Theta"
|
||||
|
||||
Anche per il tight bound abbiamo una notazione equivalente a O grande e Omega grande: _Theta grande_!
|
||||
|
||||
Diciamo che `f(n) ∈ θ(g(n))` se e solo se `∃ c_1, c_2 > 0, n_0 ≥ 0 : ∀ n ≥ n_0, c_1 * g(n) ≤ f(n) ≤ c_2 * g(n)`.
|
||||
|
||||
Ha la particolarità che non valgono tutte le proprietà degli altri due: va usata quindi con cautela!
|
||||
|
||||
## Risorse utili
|
||||
|
||||
[khanacademy.org](https://www.khanacademy.org/computing/computer-science/algorithms/asymptotic-notation/a/big-big-theta-notation)
|
||||
42
public/materials/year1/algoritmi/05_ProblemiAlgoritmici.md
Normal file
42
public/materials/year1/algoritmi/05_ProblemiAlgoritmici.md
Normal file
|
|
@ -0,0 +1,42 @@
|
|||
# Problemi algoritmici
|
||||
|
||||
Un _problema algoritmico_ è un problema matematico che si vuole provare a risolvere con un algoritmo.
|
||||
|
||||
> Dati 10 numeri, voglio sapere se sono in ordine crescente oppure no.
|
||||
|
||||
## Caterigorizzazione
|
||||
|
||||
I problemi algoritmici si dividono in tre categorie: problemi _trattabili_, problemi _intrattabili_ e problemi _irrisolvibili_.
|
||||
|
||||
### Problema trattabile
|
||||
|
||||
Perchè un problema algoritmico sia _trattabile_, deve avere **almeno un algoritmo con upper bound polinomiale**.
|
||||
|
||||
> Questo significa che il tempo impiegato da un computer per risolvere il problema rimane ragionevole, e che quindi può essere utilizzato in maniera efficiente.
|
||||
|
||||
La trattabilità è un campo ancora parecchio aperto: esistono anche tanti problemi di cui non si è ancora dimostrata la trattabilità o intrattabilità.
|
||||
|
||||
> La [fattorizzazione](https://it.wikipedia.org/wiki/Fattorizzazione) è uno di questi problemi: l'assenza di una dimostrazione è ciò che la rende uno dei pilastri della sicurezza informatica moderna.
|
||||
|
||||
### Problema intrattabile
|
||||
|
||||
Se **un problema non ha nessun algoritmo con upper bound polinomiale**, allora si dice che è **intrattabile**.
|
||||
|
||||
### Problema irrisolvibile
|
||||
|
||||
Se **non esistono algoritmi per risolvere un problema**, allora questo si dice **irrisolvibile**.
|
||||
|
||||
> [Dato un algoritmo con certi input, riusciamo a capire con un algoritmo se la sua esecuzione termina o no?](https://en.wikipedia.org/wiki/Halting_problem)
|
||||
|
||||
### Upper e lower bound di problemi
|
||||
|
||||
Si può anche trovare un _upper bound_ e un _lower bound_ per un problema, ma bisogna generalizzare di più.
|
||||
|
||||
L'**upper bound di un problema** è il minimo upper bound di tutti gli algoritmi che lo risolvono; deve esistere almeno un algoritmo che lo risolva che abbia lo stesso _upper bound_. E' praticamente il tempo migliore per risolvere il problema dato.
|
||||
|
||||
Il **lower bound di un problema** è il minimo lower bound di tutti gli algoritmi che lo risolvono; non deve esistere nemmeno un algoritmo che abbia un lower bound migliore. E' il numero assolutamente minimo di operazioni richieste, non si può fare meglio di così.
|
||||
|
||||
In particolare, abbiamo che l'_upper bound di un algoritmo_ -> l'_upper bound del suo problema_,
|
||||
e il _lower bound di un problema_ -> il _lower bound di un suo algoritmo_.
|
||||
|
||||
Generalmente, il _lower bound di un problema_ è una rappresentazione abbastanza accurata della sua difficoltà.
|
||||
5
public/materials/year1/algoritmi/06_RicercaBinaria.md
Normal file
5
public/materials/year1/algoritmi/06_RicercaBinaria.md
Normal file
|
|
@ -0,0 +1,5 @@
|
|||
# Ricerca binaria
|
||||
|
||||
Non credo di aver bisogno di studiare la ricerca binaria, quindi non ho preso appunti a riguardo.
|
||||
|
||||
Se non siete me, e state cercando informazioni a riguardo, andate a vedere su Wikipedia!
|
||||
29
public/materials/year1/algoritmi/07_DivideEtImpera.md
Normal file
29
public/materials/year1/algoritmi/07_DivideEtImpera.md
Normal file
|
|
@ -0,0 +1,29 @@
|
|||
# Divide et impera
|
||||
|
||||
Un modo efficace per risolvere un problema è di usare il metodo _divide et impera (et combina)_.
|
||||
|
||||
- _Divide_: Divido il problema in **tanti sottoproblemi**.
|
||||
- _Impera_: **Risolvo indipendentemente dal resto** ciascuno dei sottoproblemi.
|
||||
- _Combina_: **Combino** i risultati dei sottoproblemi per **risolvere il problema principale**.
|
||||
|
||||
## Ricorsione
|
||||
|
||||
Un algoritmo (o funzione) si dice _ricorsivo_ quando durante l'esecuzione **richiama sè stesso**.
|
||||
|
||||
Dato che tutti gli algoritmi devono avere termine entro un tempo finito, se scriviamo una funzione ricorsiva è fondamentale finire con un **caso base**, che non chiami ulteriormente la ricorsione.
|
||||
|
||||
Se esiste una funzione ricorsiva, allora esiste _sempre_ una _funzione iterativa_ che darà lo stesso risultato.
|
||||
|
||||
> Sul pratico, una funzione ricorsiva tipicamente è **più costosa** del suo equivalente iterativo: se possibile, quindi, la ricorsione andrebbe evitata.
|
||||
|
||||
#### Pseudocodice di esempio
|
||||
|
||||
```python
|
||||
def fattoriale(n):
|
||||
# Caso base; la ricorsione finisce e dà un risultato fisso
|
||||
if n <= 1:
|
||||
return 1
|
||||
# Caso ricorsivo; la funzione restituisce il risultato di sè stessa (ma con parametri diversi)
|
||||
else:
|
||||
return n * fattoriale(n - 1)
|
||||
```
|
||||
17
public/materials/year1/algoritmi/08_MasterTheorem.md
Normal file
17
public/materials/year1/algoritmi/08_MasterTheorem.md
Normal file
|
|
@ -0,0 +1,17 @@
|
|||
# Master Theorem
|
||||
|
||||
Il _Master Theorem_ è uno dei teoremi più importanti dell'algoritmica.
|
||||
|
||||
Esso permette di **calcolare l'upper bound di un algoritmo ricorsivo** in modo piuttosto semplice.
|
||||
|
||||
## Ipotesi
|
||||
|
||||
Dato un algoritmo:
|
||||
- Con uno o più casi base
|
||||
- Che richiama la funzione ricorsiva un numero n di volte
|
||||
|
||||
## Tesi
|
||||
|
||||
Allora, il suo upper bound avrà la formula:
|
||||
|
||||

|
||||
16
public/materials/year1/algoritmi/09_MasterTheoremSubset.md
Normal file
16
public/materials/year1/algoritmi/09_MasterTheoremSubset.md
Normal file
|
|
@ -0,0 +1,16 @@
|
|||
# Caso particolare del Master Theorem
|
||||
|
||||
## Ipotesi
|
||||
|
||||
Se:
|
||||

|
||||
|
||||
Ovvero, se la dimensione dell'input viene divisa ad ogni ciclo da una costante b, è polinomiale e il caso base è costante...
|
||||
|
||||
## Tesi
|
||||
|
||||
Allora:
|
||||

|
||||
|
||||
> In pratica, se il costo dominante è quello della parte "fissa" dell'algoritmo, esso sarà `O(n^d)`, mentre se il costo dominante è quello delle chiamate ricorsive, esso sarà `O(n^{log_b e})`.
|
||||
> Se nessuno dei due è dominante... si dividono circa in parti uguali, creando un costo di `O(n^d log n)`.
|
||||
50
public/materials/year1/algoritmi/10_Ordinamento.md
Normal file
50
public/materials/year1/algoritmi/10_Ordinamento.md
Normal file
|
|
@ -0,0 +1,50 @@
|
|||
# Ordinamento
|
||||
|
||||
Un problema molto frequente nell'informatica consiste nell'**ordinare efficientemente grandi quantità di elementi**.
|
||||
|
||||
Esistono [tantissimi](https://it.wikipedia.org/wiki/Algoritmo_di_ordinamento) algoritmi per effettuare l'ordinamento.
|
||||
L'**efficienza** di ciascuno **varia** di caso in caso: alcuni sono estremamente efficienti se quasi tutti i numeri sono già nell'ordine giusto; altri, invece, potrebbero impiegare tantissimo tempo.
|
||||
|
||||
In termini matematici, abbiamo:
|
||||
|
||||
- **Input:** A[n]
|
||||
- **Output:** B, ∀ i < n, A[i] ≤ A[i+1]
|
||||
|
||||
## Ordinamento tramite confronto
|
||||
|
||||
L'ordinamento "tradizionale" è detto _ordinamento tramite confronto_: funziona sempre, e **non ha altri modi di ottenere informazioni** se non con l'operazione logica di confronto tra i dati.
|
||||
|
||||
### Limiti
|
||||
|
||||
E' un problema risolto: è dimostrabile che il suo **lower bound** è **`Ω(n log n)`**; possiamo quindi dire che qualsiasi algoritmo di ordinamento è in `Ω(n log n)`, e se riusciamo a trovare un algoritmo di ordinamento in `O(n log n)` siamo riusciti a raggiungere il massimo dell'efficienza.
|
||||
|
||||
#### Dimostrazione
|
||||
|
||||
Consideriamo **tutte le possibili permutazioni** della sequenza da ordinare: sono `n!`.
|
||||
|
||||
Per ogni confronto che effettuiamo, **riduciamo la quantità di permutazioni** correttamente ordinate; prima o poi, rimarrà **una sola possibilità**.
|
||||
|
||||
**TODO, non trovo la spiegazione corretta!**
|
||||
|
||||
### Esempi
|
||||
|
||||
Algoritmi che effettuano l'ordinamento tramite confronto sono:
|
||||
- _Bubble sort_
|
||||
- _Merge sort_
|
||||
- _Insertion sort_
|
||||
- _Quick sort_
|
||||
- _Heap sort_
|
||||
- E tanti, tanti altri!
|
||||
|
||||
## Ordinamento con altri mezzi
|
||||
|
||||
Esistono algoritmi che ricavano informazioni in altri modi, diversi dal confronto.
|
||||
|
||||
Essi possono avere un lower bound più basso di `O(n log n)`, però hanno spesso limitazioni sul loro utilizzo.
|
||||
|
||||
### Esempi
|
||||
|
||||
- _Counting sort_, indicizza i valori da ordinare
|
||||
- _Radix sort_, guarda singolarmente le cifre dei valori
|
||||
- _Sleep sort_, sfrutta i thread e la funzione sleep per ordinare valori
|
||||
- E altri ancora!
|
||||
42
public/materials/year1/algoritmi/11_InsertionSort.md
Normal file
42
public/materials/year1/algoritmi/11_InsertionSort.md
Normal file
|
|
@ -0,0 +1,42 @@
|
|||
# Insertion sort
|
||||
|
||||
L'_insertion sort_ è una soluzione **iterativa** all'ordinamento per confronto.
|
||||
|
||||
## Funzionamento
|
||||
|
||||
Considero la sequenza divisa in **due parti**: una parte **ordinata** e una parte **non ordinata**.
|
||||
|
||||
Parto dal primo elemento della lista: è sempre ordinato con sè stesso.
|
||||
Poi, aggiungo uno alla volta i numeri della parte non ordinata a quella ordinata; prima trovo in quale posizione dovrò andare a mettere il numero, poi **faccio slittare tutti i numeri dopo quella posizione** avanti di 1, in modo da **creare lo spazio** in cui infine **inserirò** il numero.
|
||||
|
||||
## Costo computazionale
|
||||
|
||||
| Categoria | Upper bound | Lower bound | Tight bound |
|
||||
|-----------|-------------|-------------|-------------|
|
||||
| Tempo | `O(n²)` | `Ω(n)` | - |
|
||||
|
||||
Nel _caso migliore_ (**lista già ordinata**), il numero da inserire è già nella posizione giusta, quindi non devo effettuare altri confronti oltre il primo, rendendo il lower bound dell'algoritmo `Ω(n)`.
|
||||
|
||||
Nel _caso peggiore_ (**lista nell'ordine inverso**), dobbiamo confrontare il numero da inserire con tutti gli altri nella parte ordinata: dobbiamo allora eseguire `1+2+3+4+5+… = \frac{(n-1)(n)}{2}` confronti; ciò significa che l'upper bound è `O(n²)`!
|
||||
|
||||
## Pseudocodice
|
||||
|
||||
```python
|
||||
def insertion_sorted(lista):
|
||||
# Itero su tutti i numeri della lista, dal primo all'ultimo.
|
||||
for divisore_ord in range(len(lista)):
|
||||
# Partendo dalla posizione attuale, creo l'indice di divisione numeri ordinati maggiori e minori
|
||||
divisore_magg = divisore_ord
|
||||
# Faccio slittare avanti i numeri maggiori di quello che stiamo inserendo
|
||||
# Se l'indice divisore_magg raggiunge 0, vuol dire che tutti i numeri della lista sono maggiori del numero attuale
|
||||
while divisore_magg >= 0 and lista[divisore_magg-1] > lista[divisore_magg]:
|
||||
# Scambio la posizione dei due elementi con gli indici specificati
|
||||
# Funzione inventata
|
||||
lista[divisore_magg], lista[divisore_magg-1] = lista[divisore_magg-1], lista[divisore_magg]
|
||||
# Diminuisco il separatore di 1
|
||||
divisore_magg -= 1
|
||||
```
|
||||
|
||||
## Visualizzazione
|
||||
|
||||
[visualgo.net](https://visualgo.net/bn/sorting)
|
||||
102
public/materials/year1/algoritmi/11_MergeSort.md
Normal file
102
public/materials/year1/algoritmi/11_MergeSort.md
Normal file
|
|
@ -0,0 +1,102 @@
|
|||
# Merge sort
|
||||
|
||||
Il _merge sort_ è una soluzione **ricorsiva** all'ordinamento per confronto.
|
||||
|
||||
## Funzionamento
|
||||
|
||||
Per questo algoritmo, utilizziamo la tecnica del **divide et impera**.
|
||||
|
||||
1. _Divide_: Divido A in **due parti**.
|
||||
2. _Impera_: Metto **separatamente in ordine** le parti.
|
||||
3. _Unisci_: **Unisco** le due parti.
|
||||
|
||||
Consideriamo come **caso base** della ricorsione una parte composta da un numero, che ovviamente è già ordinata con sè stessa.
|
||||
|
||||
### Merge
|
||||
|
||||
Per **unire le due parti** usiamo una funzione detta `merge()`.
|
||||
|
||||
Costruiamo una nuova sequenza uguale alla sequenza 1, ma **aggiungiamo alla fine un valore sentinella** sempre maggiore di tutti gli elementi contenuti.
|
||||
|
||||
> ```
|
||||
> | 1 | 3 | 7 | 8 | ∞ |
|
||||
> ```
|
||||
|
||||
Facciamo **la stessa cosa** per la sequenza due.
|
||||
|
||||
> ```
|
||||
> | 2 | 4 | 5 | 6 | ∞ |
|
||||
> ```
|
||||
|
||||
Prendo i primi numeri delle due sequenze e **metto il più piccolo nella sequenza iniziale**.
|
||||
|
||||
> ```
|
||||
> | 1 | 2 | 3 | | | | | |
|
||||
> | | | 7 | 8 | ∞ |
|
||||
> | | 4 | 5 | 6 | ∞ |
|
||||
> ```
|
||||
|
||||
**Continuo** finchè non ho messo tutti i numeri; **grazie alla sentinella non usciremo mai dalla sequenza**, in quanto essa è sempre maggiore di tutti gli altri numeri.
|
||||
|
||||
> ```
|
||||
> | 1 | 2 | 3 | 4 | 5 | 6 | | |
|
||||
> | | | 7 | 8 | ∞ |
|
||||
> | | | | | ∞ |
|
||||
> ```
|
||||
|
||||
Quando **rimangono solo le sentinelle** significa che abbiamo aggiunto tutti gli elementi, e quindi abbiamo finito.
|
||||
|
||||
> ```
|
||||
> | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|
||||
> | | | | | ∞ |
|
||||
> | | | | | ∞ |
|
||||
> ```
|
||||
|
||||
|
||||
## Costo computazionale
|
||||
|
||||
| Categoria | Upper bound | Lower bound | Tight bound |
|
||||
|-----------|-------------|-------------|-------------|
|
||||
| Tempo | `O(n log n)` | `Ω(n log n)` | **`θ(n log n)`** |
|
||||
|
||||
Il merge sort è un algoritmo ricorsivo con un **caso base in tempo costante** e che **richiama sè stesso 2 volte**.
|
||||
|
||||
```latex
|
||||
T(n) =\\
|
||||
\\
|
||||
Θ(1) \qquad n=1\\
|
||||
2 T(\frac{n}{2}) + Θ(n) \qquad n \neq 1
|
||||
```
|
||||
|
||||
Applicando il **caso particolare del Master Theorem**, otteniamo:
|
||||
|
||||
```latex
|
||||
T(n) =\\
|
||||
\\
|
||||
Θ(1) \qquad n=1\\
|
||||
Θ(n log n) \qquad n \neq 1
|
||||
```
|
||||
|
||||
## Pseudocodice
|
||||
|
||||
```python
|
||||
def merge_sorted(part):
|
||||
# Caso base
|
||||
if len(part) == 1:
|
||||
return part
|
||||
# Divide
|
||||
middle = len(part) // 2
|
||||
part_a = part[:middle]
|
||||
part_b = part[middle:]
|
||||
# Impera
|
||||
sort_a = merge_sorted(part_a)
|
||||
sort_b = merge_sorted(part_b)
|
||||
# Combina
|
||||
return merge(sort_a, sort_b)
|
||||
```
|
||||
|
||||
## Visualizzazione
|
||||
|
||||
[hackerearth.com](https://www.hackerearth.com/practice/algorithms/sorting/merge-sort/visualize/)
|
||||
|
||||
[visualgo.net](https://visualgo.net/bn/sorting) (Nota: visualizza solo la fase _Unisci_ del sort)
|
||||
131
public/materials/year1/algoritmi/11_QuickSort.md
Normal file
131
public/materials/year1/algoritmi/11_QuickSort.md
Normal file
|
|
@ -0,0 +1,131 @@
|
|||
# Quick sort
|
||||
|
||||
Il _quick sort_ è un altro approccio **ricorsivo** all'ordinamento per confronto.
|
||||
|
||||
## Funzionamento
|
||||
|
||||
Anche qui, applichiamo il **divide et impera**.
|
||||
|
||||
1. _Divide_: Scelgo un **pivot** qualsiasi all'interno della lista. Metto alla sua **sinistra tutti i numeri minori** e alla sua **destra tutti i numeri maggiori**.
|
||||
2. _Impera_: Eseguo un **quick sort su entrambe le sottoliste**.
|
||||
|
||||
### Esempi
|
||||
|
||||
#### Iterazione con partizioni bilanciate
|
||||
|
||||
Osserviamo come si formi una partizione con tre elementi e una con quattro.
|
||||
|
||||
```
|
||||
|¦ [2] 8 7 1 3 5 6 {4}
|
||||
2 |¦ [8] 7 1 3 5 6 {4}
|
||||
2 |8 ¦ [7] 1 3 5 6 {4}
|
||||
2 |8 ¦ [7] 1 3 5 6 {4}
|
||||
2 |8 7 ¦ [1] 3 5 6 {4}
|
||||
2 1 |7 8 ¦ [3] 5 6 {4}
|
||||
2 1 3 |8 7 ¦ [5] 6 {4}
|
||||
2 1 3 |8 7 5 ¦ [6] {4}
|
||||
2 1 3 |8 7 5 6 ¦ [{4}]
|
||||
[2 1 3] {4} [8 5 6 7]
|
||||
```
|
||||
|
||||
#### Iterazione con partizioni sbilanciate
|
||||
|
||||
Osserviamo come si formi una partizione con **zero elementi** e una con tre.
|
||||
|
||||
```
|
||||
|¦ [4] 7 3 {1}
|
||||
|4 ¦ [7] 3 {1}
|
||||
|4 7 |¦ [3] {1}
|
||||
|4 7 3 |¦ [{1}]
|
||||
[] {1} [4 7 3]
|
||||
```
|
||||
|
||||
## Costo computazionale
|
||||
|
||||
| Categoria | Upper bound | Lower bound | Tight bound |
|
||||
|-----------|-------------|-------------|-------------|
|
||||
| Tempo | `O(n²)` | `Ω(n log n)` | - |
|
||||
|
||||
Il costo della funzione è dato dalla somma del costo per **dividere in due partizioni** con il costo per realizzare il **Quick sort delle due sottopartizioni**
|
||||
|
||||
Possiamo applicare allora il **Master Theorem generale**:
|
||||
|
||||
```latex
|
||||
T(n)\\
|
||||
=\\
|
||||
Θ(1) \qquad per\ n = 1\\
|
||||
T(q) + T(dim_lista - pivot - 1) + Θ(n) \qquad per\ n > 1
|
||||
```
|
||||
|
||||
### Il caso migliore
|
||||
|
||||
Se il pivot `q` è la **mediana della partizione** che stiamo ordinando, si vengono a creare due _sottopartizioni bilanciate_, e sostituendo otteniamo:
|
||||
|
||||
```latex
|
||||
T(n)\\
|
||||
=\\
|
||||
Θ(1) \qquad per\ n = 1\\
|
||||
2 T(\frac{n}{2}) + Θ(n) \qquad per\ n > 1
|
||||
```
|
||||
|
||||
Possiamo allora applicare il **Master Theorem particolare**:
|
||||
|
||||
```latex
|
||||
T(n)\\
|
||||
=\\
|
||||
Θ(1) \qquad per\ n = 1\\
|
||||
Θ(n log n) \qquad per\ n > 1
|
||||
```
|
||||
|
||||
### Il caso peggiore
|
||||
|
||||
Se il pivot è uno degli **estremi dell'array**, si creano due _partizioni sbilanciate_: una delle due sottoliste è sempre vuota!
|
||||
Allora:
|
||||
|
||||
```latex
|
||||
T(n) = T(n-1) + Θ(n)\\
|
||||
= T(n-2) + Θ(n-1) + Θ(n)\\
|
||||
= T(n-3) + Θ(n-2) + Θ(n-1) + Θ(n)\\
|
||||
= …
|
||||
∈ Θ(n^2)
|
||||
```
|
||||
|
||||
> "Non date da mangiare sequenze ordinate al Quicksort, gli sono indigeste."
|
||||
|
||||
## Pseudocodice
|
||||
|
||||
```python
|
||||
def partition(partizione, inizio, fine):
|
||||
"""Dividi una partizione in due, usando l'ultimo elemento come pivot.
|
||||
|
||||
Note utili:
|
||||
partizione[fine] è il pivot
|
||||
partizione[maggiori] è il primo numero dei maggiori
|
||||
partizione[non_iterati] è l'elemento su cui si sta iterando al momento"""
|
||||
# Crea il primo separatore (la | pipe nell'esempio)
|
||||
maggiori = inizio
|
||||
# Crea il secondo separatore (la ¦ broken pipe nell'esempio)
|
||||
non_iterati = inizio
|
||||
# Itera su ogni numero tra inizio e fine (escluso!)
|
||||
while non_iterati < fine:
|
||||
# Se l'elemento su cui stiamo iterando è minore del pivot
|
||||
if partizione[non_iterati] <= partizione[fine]:
|
||||
# Mettilo nell'insieme dei minori, scambiandolo con il primo numero dei maggiori e incrementando il primo separatore
|
||||
partizione[maggiori], partizione[non_iterati] = partizione[non_iterati], partizione[maggiori]
|
||||
maggiori += 1
|
||||
# Incrementa sempre il secondo separatore
|
||||
non_iterati += 1
|
||||
# Inserisci il pivot tra le due sottopartizioni create,
|
||||
partizione[fine], partizione[non_iterati] = partizione[non_iterati], partizione[fine]
|
||||
return maggiori
|
||||
```
|
||||
|
||||
## Visualizzazione
|
||||
|
||||
[visualgo.net](https://visualgo.net/bn/sorting) (Nota: invece che prendere l'ultimo numero come pivot prende il primo, cambiando leggermente l'algoritmo.)
|
||||
|
||||
## Note per l'esame
|
||||
|
||||
> La domanda che fa sempre è **"Qual è la sequenza di pivot utilizzata?"**
|
||||
|
||||
> Elementi da soli _non_ vengono presi come pivot!
|
||||
95
public/materials/year1/algoritmi/12_CountingSort.md
Normal file
95
public/materials/year1/algoritmi/12_CountingSort.md
Normal file
|
|
@ -0,0 +1,95 @@
|
|||
# Counting sort
|
||||
|
||||
Il _counting sort_ è un approccio diverso all'ordinamento: **non usa il confronto**!
|
||||
|
||||
## Requisiti
|
||||
|
||||
Il counting sort può essere utilizzato solo su **sequenze di numeri interi**, e solo se **siamo a conoscenza del minimo e del massimo** dei numeri contenuti nell'array, ed essi non sono troppo distanti uno dall'altro.
|
||||
(La memoria occupata dal counting sort aumenta linearmente con la differenza tra minimo e massimo!)
|
||||
|
||||
Per semplicità, consideriamo il **minimo `0`**.
|
||||
L'input allora sarà una sequenza di interi `A`, e il valore del **massimo `k`**, tale che `∀ n ∈ A, 0 \leq n \leq K`.
|
||||
|
||||
## Funzionamento
|
||||
|
||||
Il counting sort **conta le ripetizioni** delle chiavi nella sequenza originale e in seguito **sovrascrive i valori** della sequenza con i valori ordinati ripetuti il numero di volte che sono stati individuati nella sequenza.
|
||||
|
||||
> ```
|
||||
> 1 4 5 3 4 1 4 2 5 1
|
||||
> ```
|
||||
>
|
||||
> L'`1` appare 3 volte, il `2` 1 volta, il `3` 1 volta, il `4` tre volte e il `5` due volte.
|
||||
>
|
||||
> La sequenza viene quindi così sovrascritta:
|
||||
> ```
|
||||
> 1 1 1 3 4 1 4 2 5 1 # Sovrascriviamo la sequenza con 1 ripetuto 3 volte
|
||||
> 1 1 1 2 3 4 4 4 5 1 # Sovrascriviamo la sequenza con 2, 3, 4 ripetuti rispettivamente 1 1 e 3 volte
|
||||
> 1 1 1 2 3 4 4 4 5 5 # Sovrascriviamo la sequenza con 5 ripetuto 2 volte: abbiamo finito!
|
||||
> ```
|
||||
|
||||
Esiste anche una **versione stabile** del counting sort che, invece che sovrascrivere, **sposta i valori**, mantenendo le informazioni aggiuntive nel caso invece che interi fossero altri tipi di dati.
|
||||
|
||||
## Costo computazionale
|
||||
|
||||
| Categoria | Upper bound | Lower bound | Tight bound |
|
||||
|-----------|-------------|-------------|-------------|
|
||||
| Tempo | `O(k + n)` | `Ω(k + n)` | **`θ(k + n)`** |
|
||||
|
||||
L'algoritmo è composto da quattro parti:
|
||||
- Ricerca del minimo e massimo (in `θ(n)`)
|
||||
- Inizializzazione dell'indice (in `θ(k)`)
|
||||
- Conteggio dei numeri (in `θ(n)`)
|
||||
- Sovrascrittura dei numeri (in `θ(k + n)`)
|
||||
|
||||
`2 + O(k) + O(n) + O(k + n) -> O(k + n)`
|
||||
|
||||
Notiamo che `k` è costante, l'algoritmo è `O(n)`, estremamente efficiente.
|
||||
|
||||
## Pseudocodice
|
||||
|
||||
```python
|
||||
def counting_sort(lista: typing.List[int]):
|
||||
"""Ordina in-place una lista con il counting sort."""
|
||||
# Trovo la dimensione della lista
|
||||
dim = len(lista)
|
||||
# Trovo il massimo e il minimo all'interno della lista
|
||||
minimo = min(lista)
|
||||
massimo = max(lista)
|
||||
# Creo l'indice dei numeri, in modo che sia lungo k e pieno di 0
|
||||
indice = [0 for _ in range(minimo, massimo+1)]
|
||||
# Conto i numeri presenti, scorrendo su lista e aggiungendo 1 al numero corrispondente
|
||||
for i in range(dim):
|
||||
indice[lista[i]] += 1
|
||||
# Sovrascrivo i numeri nella lista
|
||||
count = 0
|
||||
for pos, val in enumerate(indice):
|
||||
for _ in range(val):
|
||||
indice[count] = pos
|
||||
count += 1
|
||||
|
||||
def stable_counting_sorted(lista: typing.List[int], k: int) -> typing.List[int]:
|
||||
"""Ordina stabilmente una lista con il counting sort stabile, e restituiscila."""
|
||||
# Trovo la dimensione della lista
|
||||
dim = len(lista)
|
||||
# Trovo il massimo e il minimo all'interno della lista
|
||||
minimo = min(lista)
|
||||
massimo = max(lista)
|
||||
# Creo l'indice dei numeri, in modo che sia lungo k e pieno di 0
|
||||
indice = [0 for _ in range(minimo, massimo+1)]
|
||||
# Conto i numeri presenti, scorrendo su lista e aggiungendo 1 al numero corrispondente
|
||||
for i in range(dim):
|
||||
indice[lista[i]] += 1
|
||||
# Faccio diventare l'indice "il numero di numeri \leq i"
|
||||
for i in range(len(indice)):
|
||||
if i == 0:
|
||||
continue
|
||||
indice[i] += indice[i-1]
|
||||
assert indice[-1] == dim
|
||||
# Creo una nuova lista, che sarà quella che verrà restituita
|
||||
nuova = [None for _ in range(dim)]
|
||||
# Inizio a posizionare i numeri, al contrario
|
||||
for i in range(0, dim, -1):
|
||||
nuova[indice[lista[i]]] = lista[i]
|
||||
indice[lista[i]] -= 1
|
||||
return nuova
|
||||
```
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
## Introduzione alle Strutture Dati
|
||||
|
||||
Una _struttura dati_ è un modo in cui si possono organizzare i dati di un programma.
|
||||
|
||||
Si possono definire in due modi: **elementari** e **astratte**.
|
||||
|
||||
### Strutture dati elementari
|
||||
|
||||
Le strutture _elementari_ dipendono strettamente dal modo in cui vengono memorizzati i dati.
|
||||
|
||||
> **Array** e **liste** sono strutture dati elementari: sono definite dicendo come sono memorizzati i dati, rispettivamente, in celle contigue di memoria e da una serie di nodi con un valore e che puntano al successivo.
|
||||
|
||||
### Strutture dati astratte
|
||||
|
||||
Le strutture _astratte_ sono separate dal modo in cui vengono memorizzati i dati, sono più ad alto livello, e si definiscono descrivendo le **proprietà** della struttura e i **metodi** che su di essa possono essere effettuate.
|
||||
|
||||
> Una _classe_ in un qualsiasi linguaggio di programmazione è una struttura dati astratta.
|
||||
|
||||
> Una _pila_ astratta:
|
||||
> - memorizza dati tutti dello stesso tipo
|
||||
> - `pop()`, estrae dalla pila l'ultimo valore inserito
|
||||
> - `push(val)`, aggiunge alla pila un valore
|
||||
> - `top()`, permette di vedere l'ultimo valore inserito nella pila
|
||||
> - `vuota()`, dice se la pila è vuota oppure no.
|
||||
20
public/materials/year1/algoritmi/14_Array.md
Normal file
20
public/materials/year1/algoritmi/14_Array.md
Normal file
|
|
@ -0,0 +1,20 @@
|
|||
# Array
|
||||
|
||||
Un _array_ è sequenza di dati di **lunghezza conosciuta**, tutti dello **stesso tipo** e di una **dimensione fissa**, immagazzinata in **blocchi di memoria contigui**.
|
||||
|
||||
## Proprietà
|
||||
|
||||
- E' possibile accedere a tutti i blocchi di memoria conoscendo la loro **posizione relativa al primo** elemento.
|
||||
|
||||
## Metodi
|
||||
|
||||
```python
|
||||
class Array:
|
||||
def __init__(self, size, type=int): "Crea un array di dimensione size di elementi di tipo int."
|
||||
def __getitem__(self, index): "Restituisci il valore alla posizione index."
|
||||
def __setitem__(self, index, value): "Cambia il valore alla posizione index."
|
||||
```
|
||||
|
||||
### Costo computazionale
|
||||
|
||||
Tutte le operazioni su un array sono in **accesso immediato `O(1)`**!
|
||||
38
public/materials/year1/algoritmi/14_Lista.md
Normal file
38
public/materials/year1/algoritmi/14_Lista.md
Normal file
|
|
@ -0,0 +1,38 @@
|
|||
# Lista
|
||||
|
||||
Una _lista_ è una sequenza di dati immagazzinata in **blocchi di memoria qualsiasi**.
|
||||
|
||||
## Proprietà
|
||||
|
||||
Ogni dato ha un **riferimento** alla collocazione di memoria **successiva** (un puntatore): insieme, sono detti un _nodo_.
|
||||
|
||||
E' di **natura ricorsiva**: qualsiasi nodo di una lista può essere visto come inizio della lista con sè stesso e i suoi successivi.
|
||||
|
||||
## Metodi
|
||||
|
||||
```python
|
||||
class LinkedList:
|
||||
def __init__(self, value, next: typing.Optional[Node] = None):
|
||||
self.value = value
|
||||
self.next: typing.Optional[Node] = next
|
||||
|
||||
def is_empty(self) -> bool: "Restituisce se la lista è vuota o no."
|
||||
def is_full(self) -> bool: "Restituisce se la lista è piena o no.
|
||||
def append(self, value): "Aggiunge un nuovo elemento in testa alla lista."
|
||||
def insert(self, value, index): "Inserisce un elemento dopo il nodo in posizione index."
|
||||
def insert_node(self, value, node): "Inserisce un nuovo elemento subito dopo un dato nodo."
|
||||
def find(self, node) -> int: "Trova l'indice del nodo."
|
||||
def delete(self, value): "Elimina il primo nodo con quel valore dalla lista."
|
||||
def delete_node(self, node): "Elimina il nodo dalla lista."
|
||||
def forward(self, index) -> Node: "Restituisce il nodo in posizione index."
|
||||
```
|
||||
|
||||
### Costo computazionale
|
||||
|
||||
#### `List.forward(index)`
|
||||
|
||||
Per raggiungere l'`n`-esimo elemento, bisogna _scorrere tutti gli elementi prima di esso_: è dunque un **accesso sequenziale** in **`O(n)`**.
|
||||
|
||||
## Visualizzazione
|
||||
|
||||
[visualgo.net](https://visualgo.net/en/list)
|
||||
32
public/materials/year1/algoritmi/15_Coda.md
Normal file
32
public/materials/year1/algoritmi/15_Coda.md
Normal file
|
|
@ -0,0 +1,32 @@
|
|||
# Coda (Queue)
|
||||
|
||||
Una _coda_ è come una pila, ma segue la strategia **First In, First Out** (il primo inserito sarà il primo a essere estratto).
|
||||
|
||||
## Proprietà
|
||||
|
||||
- I dati vi possono essere aggiunti solo tramite il **metodo `enqueue()`**
|
||||
- I dati possono essere estratti solo tramite il **metodo `dequeue()`**
|
||||
- Verranno restituiti i valori inseriti secondo la strategia **First In, First Out** (il primo inserito sarà il primo a essere estratto).
|
||||
|
||||
> Hai presente quando fai la fila per pagare al supermercato? Beh, è quello, però non si possono superare le altre persone in nessun modo.
|
||||
|
||||
## Metodi
|
||||
|
||||
```python
|
||||
class Queue:
|
||||
def __init__(self): "Crea una nuova coda."
|
||||
def is_empty(self) -> bool: "Restituisce vero se la coda è vuota."
|
||||
def enqueue(self, data): "Aggiunge un dato alla coda."
|
||||
def first(self) -> ...: "Restituisce il primo dato della coda."
|
||||
def dequeue(self) -> ...: "Restituisce il primo dato della coda e lo rimuove."
|
||||
```
|
||||
|
||||
## Implementazione tramite lista
|
||||
|
||||
Posso implementare la coda con una lista, ma per realizzare l'implementazione più efficiente devo tenere anche un puntatore all'ultimo elemento della coda, in modo da non doverla scorrere ogni volta che voglio effettuare un'operazione.
|
||||
|
||||
Chiamiamo i due puntatori `head` e `tail` rispettivamente.
|
||||
|
||||
## Visualizzazione
|
||||
|
||||
[visualgo.net](https://visualgo.net/en/list)
|
||||
34
public/materials/year1/algoritmi/15_Pila.md
Normal file
34
public/materials/year1/algoritmi/15_Pila.md
Normal file
|
|
@ -0,0 +1,34 @@
|
|||
# Pila (Stack)
|
||||
|
||||
Una _pila_ è una struttura dati contenente **valori omogenei**.
|
||||
|
||||
## Proprietà
|
||||
|
||||
- I dati vi possono essere aggiunti solo tramite il **metodo `push()`**
|
||||
- I dati possono essere estratti solo tramite il **metodo `pop()`**
|
||||
- Verranno restituiti i valori inseriti secondo la strategia **Last In, First Out** (l'ultimo inserito sarà il primo a essere estratto).
|
||||
|
||||
> Ci si può immaginare una pila di libri, da cui si può solo prendere un libro alla volta, quello più in alto.
|
||||
|
||||
## Metodi
|
||||
|
||||
```python
|
||||
class Stack:
|
||||
def __init__(self): "Crea una nuova pila."
|
||||
def is_empty(self) -> bool: "Restituisce vero se la pila è vuota."
|
||||
def push(self, data): "Aggiunge un dato alla pila."
|
||||
def top(self) -> ...: "Restituisce il primo dato della pila."
|
||||
def pop(self) -> ...: "Restituisce il primo dato della pila e lo rimuove."
|
||||
```
|
||||
|
||||
## Implementazione tramite lista
|
||||
|
||||
Utilizzando una lista possiamo realizzare una pila!
|
||||
|
||||
La direzione dei puntatori sarà dall'ultimo al primo, che non punterà più a nessuno.
|
||||
|
||||
Il costo di tutti i metodi è `Θ(1)`!
|
||||
|
||||
## Visualizzazione
|
||||
|
||||
[visualgo.net](https://visualgo.net/en/list)
|
||||
77
public/materials/year1/algoritmi/16_AlberoRadicato.md
Normal file
77
public/materials/year1/algoritmi/16_AlberoRadicato.md
Normal file
|
|
@ -0,0 +1,77 @@
|
|||
# Albero radicato
|
||||
|
||||
Un _albero radicato_ è una struttura dati di **natura ricorsiva** che organizza i dati in maniera **non-lineare**.
|
||||
|
||||
## Proprietà
|
||||
|
||||
- Ogni nodo dell'albero ha un **unico genitore**: `∀ (padre, figlio), (padre' figlio) ∈ E \implies padre = padre'`
|
||||
- Ogni nodo dell'albero può avere **un numero qualsiasi di figli**.
|
||||
<!---->
|
||||
- I **nodi superiori al padre** vengono chiamati _antenati_.
|
||||
- I **nodi inferiori ai figli** vengono chiamati _discendenti_.
|
||||
<!---->
|
||||
- Nodi **senza padre** sono detti _radice_: `\notexists (padre, radice) ∈ E`
|
||||
- Nodi **con padre e figli** sono detti _rami_ o interni.
|
||||
- Nodi **senza figli** sono detti _foglie_.
|
||||
<!---->
|
||||
- La **distanza** tra il nodo radice e i suoi discendenti è detta _livello_:
|
||||
- I figli immediati sono di livello 1.
|
||||
- I "nipoti" (figli dei figli) sono di livello 2.
|
||||
- I figli dei nipoti sono livello 3.
|
||||
- E così via.
|
||||
- Il **livello massimo** all'interno di un albero è detto _altezza_, _profondità_ oppure _h_, ed è sempre `1 ≤ h ≤ n-1`.
|
||||
<!---->
|
||||
- Un albero ha sempre `n-1` archi.
|
||||
|
||||
## Alberi particolari
|
||||
|
||||
### Alberi `d`-ari
|
||||
|
||||
Un albero _`d`-ario_ è un particolare tipo di albero che **limita il numero massimo di figli di un nodo** a `d`.
|
||||
|
||||
> Un albero _binario_ può avere **massimo 2 figli** per ogni nodo; un albero _ternario_ ne può avere **3**; un albero _`17`-ario_ ne potrà avere **17**
|
||||
|
||||
#### Alberi completi
|
||||
|
||||
Un albero `d`-ario si dice _completo_ se **tutti i nodi hanno 0 o `d` figli**, e mai una numero in mezzo.
|
||||
|
||||
#### Alberi bilanciati
|
||||
|
||||
Un albero `d`-ario si dice _bilanciato_ se **tutti i livelli eccetto l'ultimo** hanno il numero massimo di figli.
|
||||
|
||||
#### Alberi perfettamente bilanciati
|
||||
|
||||
Un albero `d`-ario si dice _perfettamente bilanciato_ se **tutti i livelli incluso l'ultimo** hanno il numero massimo di figli.
|
||||
|
||||
##### Particolarità degli alberi binari perfettamente bilanciati
|
||||
|
||||
Si può dimostrare per induzione che:
|
||||
- Hanno sempre `2^h` foglie.
|
||||
- Hanno sempre `2^{h+1}-1` (`\sum_i=0^n 2^i`) nodi.
|
||||
- L'altezza è in `Θ(log n)`.
|
||||
|
||||
## Implementazione degli alberi
|
||||
|
||||
Possiamo scegliere se usare una rappresentazione con array o con nodi e puntatori: ognuna ha vantaggi e svantaggi diversi.
|
||||
|
||||
### Implementazione tramite array
|
||||
|
||||
E' suggerito se l'albero è regolare; più è simile a un albero d-ario completo, meglio è.
|
||||
|
||||
### Implementazione tramite nodi e puntatori
|
||||
|
||||
Più adatta ad alberi irregolari.
|
||||
|
||||
Se l'albero è regolare, creiamo il numero esatto di campi:
|
||||
|
||||
- Valore
|
||||
- Figlio1
|
||||
- Figlio2
|
||||
- _Opzionale:_ Padre
|
||||
|
||||
Se un albero è irregolare, creiamo una specie di lista:
|
||||
|
||||
- Valore
|
||||
- Primo figlio
|
||||
- Prossimo fratello
|
||||
- _Opzionale:_ Padre
|
||||
25
public/materials/year1/algoritmi/17_BreadthFirstSearch.md
Normal file
25
public/materials/year1/algoritmi/17_BreadthFirstSearch.md
Normal file
|
|
@ -0,0 +1,25 @@
|
|||
#### Breadth-first search (BFS)
|
||||
|
||||
La _breadth-first search_ è un algoritmo che visita **ogni livello** dell'albero in ordine, dal più basso al più alto.
|
||||
|
||||
## Funzionamento
|
||||
|
||||
> 1. __Visita radice__
|
||||
> 2. __Visita figli__
|
||||
> 3. __Visita nipoti__
|
||||
> 4. __Visita pronipoti__
|
||||
|
||||
Si può implementare con una coda, in cui verranno inseriti i figli del nodo visitato da visitare ed estratti dopo avere completato la visita del livello attuale.
|
||||
|
||||
## Pseudocodice
|
||||
|
||||
```python
|
||||
def bfs(radice):
|
||||
c = Queue()
|
||||
c.enqueue(radice)
|
||||
while not c.is_empty():
|
||||
nodo = c.dequeue()
|
||||
print(nodo)
|
||||
for figlio in nodo.figli:
|
||||
nodo.enqueue(figlio)
|
||||
```
|
||||
31
public/materials/year1/algoritmi/17_DepthFirstSearch.md
Normal file
31
public/materials/year1/algoritmi/17_DepthFirstSearch.md
Normal file
|
|
@ -0,0 +1,31 @@
|
|||
# Depth-First Search
|
||||
|
||||
La _depth-first search_ è un algoritmo che visita **tutti i sottoalberi di un figlio** prima di passare ad un altro sfruttando la natura ricorsiva degli alberi.
|
||||
|
||||
## Funzionamento
|
||||
|
||||
Ci sono diverse versioni della depth-first search: ognuna visita la radice in un momento diverso.
|
||||
|
||||
### DFS previsita (pre-order)
|
||||
|
||||
La _DFS pre-visita_ visita la **radice per prima**, poi tutti i sottoalberi formati dai figli uno dopo l'altro.
|
||||
|
||||
> 1. __Visita radice__
|
||||
> 2. dfs_pre_order(figlio1)
|
||||
> 3. dfs_pre_order(figlio2)
|
||||
|
||||
### Postvisita (post-order)
|
||||
|
||||
La _DFS postvisita_ visita prima tutti i sottoalberi dei figli, e **alla fine la radice**.
|
||||
|
||||
> 1. dfs_post_order(figlio1)
|
||||
> 2. dfs_post_order(figlio2)
|
||||
> 3. __Visita radice__
|
||||
|
||||
### Invisita (in-order)
|
||||
|
||||
La _DFS invisita_ visita **un certo numero di figli**, poi la radice, e infine i figli restanti.
|
||||
|
||||
> 1. dfs_in_order(figlio1, 1)
|
||||
> 2. __Visita radice__
|
||||
> 3. dfs_in_order(figlio2, 1)
|
||||
|
|
@ -0,0 +1,54 @@
|
|||
# Albero binario di ricerca
|
||||
|
||||
## Proprietà
|
||||
|
||||
- Albero **binario**
|
||||
- Chiavi appartenenti ad un **insieme totalmente ordinato** (N, Q, R, ma non C)
|
||||
<!---->
|
||||
- Per ogni nodo con valore `x`, se un valore `v` è nel sottoalbero di sinistra allora `v ≤ x`, mentre se è nel sottoalbero di destra allora `v > x`.
|
||||
|
||||
## Costo computazionale
|
||||
|
||||
- Trovare un valore: `O(h)`
|
||||
- Ordinare i valori: `O(n)`
|
||||
- Trovare il minimo: `O(h)`
|
||||
- Trovare il massimo: `O(h)`
|
||||
- Inserire un elemento: `O(h)`
|
||||
- Cancellare un elemento: `O(h)`
|
||||
|
||||
`h` vale `log n` in un albero perfettamente bilanciato, e più l'albero diventa sbilanciato, più si avvicina a `n`, raggiungendola nel caso l'albero sia una lista.
|
||||
|
||||
## Pseudocodice
|
||||
|
||||
### Cancellazione ricorsiva
|
||||
|
||||
```python
|
||||
def delete(tree, key):
|
||||
if tree is not None:
|
||||
# Se ho trovato il nodo che cercavo...
|
||||
if tree.key == key:
|
||||
# E c'è una sola diramazione...
|
||||
# Semplicemente stacca il nodo come in una lista.
|
||||
if tree.left is None:
|
||||
return tree.right
|
||||
if tree.right is None:
|
||||
return tree.left
|
||||
# Altrimenti, diventa il minimo dell'albero di destra
|
||||
tree.key = tree.right.min()
|
||||
# Ed eliminalo dal sottoalbero
|
||||
tree.right = delete(tree.right, tree.key)
|
||||
# Se la chiave attuale è diversa da quella che cerchiamo, continuo a navigare l'albero
|
||||
elif tree.key < key:
|
||||
tree.left = delete(tree.left, key)
|
||||
else:
|
||||
tree.right = delete(tree.right, key)
|
||||
return tree
|
||||
```
|
||||
|
||||
## Visualizzazione
|
||||
|
||||
[visualgo.net](https://visualgo.net/en/bst)
|
||||
|
||||
## Approfondimenti
|
||||
|
||||
Esistono alberi più avanzati che mantengono le proprietà degli alberi binari di ricerca, ma che si autobilanciano, come il [Red Black Tree](https://it.wikipedia.org/wiki/RB-Albero).
|
||||
140
public/materials/year1/algoritmi/19_HeapBinario.md
Normal file
140
public/materials/year1/algoritmi/19_HeapBinario.md
Normal file
|
|
@ -0,0 +1,140 @@
|
|||
# Heap binario
|
||||
|
||||
L'_heap binario_ è un **albero binario bilanciato a sinistra**.
|
||||
|
||||
## Proprietà
|
||||
|
||||
- _Proprietà strutturale_:
|
||||
- L'albero è **perfettamente bilanciato** in tutti i livelli tranne l'ultimo
|
||||
- Nell'ultimo livello, le foglie occupano le **posizioni più a sinistra** possibili
|
||||
- _Proprietà di ordinamento_:
|
||||
- La chiave di un qualsiasi nodo è **più piccola** di tutte quelle dei nodi **del suo sottoalbero**
|
||||
|
||||
## Metodi
|
||||
|
||||
```python
|
||||
class Heap:
|
||||
def __init__(self, H): ...
|
||||
def _heapify_ancestors(self, i): "Ripristina le proprietà dell'heap per il nodo all'indice specificato e i suoi genitori."
|
||||
def minimum(self): "Restituisce la chiave con il valore minimo in H."
|
||||
def decrease_value(self, index, new_value): "Diminuisce il valore della chiave all'indice index a new_value."
|
||||
def insert(self, value): "Inserisci un nuovo valore nell'albero."
|
||||
def _heapify_children(self, i): "Ripristina le proprietà dell'heap per il nodo all'indice specificato e i suoi figli."
|
||||
def pop(self): "Restituisce la chiave con il valore minimo, e la elimina."
|
||||
def from_list(l): "Crea un heap da una lista."
|
||||
```
|
||||
|
||||
## Implementazione con un array
|
||||
|
||||
Possiamo implementare l'albero utilizzando un array con le chiavi dell'albero memorizzate nell'ordine _breadth-first_.
|
||||
|
||||
L'indice del figlio sinistro può essere trovato a `2i+1`, mentre l'indice del figlio sinistro può essere trovato a `2i+2`; il genitore è a `i//2-1`.
|
||||
|
||||
### Pseudocodice
|
||||
|
||||
```python
|
||||
class Heap:
|
||||
def __init__(self, size):
|
||||
self.array = Array(size) # Il tipo Array non esiste; consideriamolo pseudocodice
|
||||
self.next_value = 0
|
||||
|
||||
def _heapify_ancestors(self, index)
|
||||
"""Ripristina le proprietà dell'heap per il nodo all'indice specificato e i suoi genitori.
|
||||
|
||||
Costo:
|
||||
O(log n)"""
|
||||
# Trovo l'indice del genitore
|
||||
parent = index // 2 - 1
|
||||
# Controllo se viene mantenuta la proprietà di ordinamento dell'heap
|
||||
if self.array[index] < self.array[parent]:
|
||||
# Scambio i valori dei due nodi
|
||||
self.array[index], self.array[parent] = self.array[parent], self.array[index]
|
||||
# Faccio la stessa cosa con il genitore
|
||||
self._heapify(parent)
|
||||
|
||||
|
||||
def minimum(self):
|
||||
"""Restituisce la chiave con il valore minimo in H.
|
||||
|
||||
Costo:
|
||||
O(1)"""
|
||||
return self.array[0]
|
||||
|
||||
def decrease_value(self, index, new_value):
|
||||
"""Diminuisce il valore della chiave all'indice index a new_value.
|
||||
|
||||
Costo:
|
||||
O(log n)"""
|
||||
# Diminuisco il valore del nodo
|
||||
self.array[index] = new_value
|
||||
# Aggiorno l'heap
|
||||
self._heapify(index)
|
||||
|
||||
def insert(self, value):
|
||||
"""Inserisci un nuovo valore nell'albero.
|
||||
|
||||
Costo:
|
||||
O(log n)"""
|
||||
# Trovo l'indice in cui inserire il valore
|
||||
index = self.next_index
|
||||
# Aggiungo il valore in fondo
|
||||
self.array[index] = value
|
||||
# Aggiorno l'heap
|
||||
self._heapify(index)
|
||||
|
||||
def _heapify_children(self, index):
|
||||
"""Ripristina le proprietà dell'heap per il nodo all'indice specificato e i suoi figli.
|
||||
|
||||
Costo:
|
||||
O(log n)"""
|
||||
# Trovo l'indice dei figli
|
||||
left = index * 2 + 1
|
||||
right = index * 2 + 2
|
||||
# Mi assicuro che i figli esistano
|
||||
try:
|
||||
# Guardo quale dei figli è maggiore
|
||||
if self.array[left] > self.array[right]:
|
||||
# Scambio i valori
|
||||
self.array[left], self.array[index] = self.array[index], self.array[left]
|
||||
# Ripeto la procedura sul figlio modificato
|
||||
self._heapify_children(left)
|
||||
else:
|
||||
# Scambio i valori
|
||||
self.array[right], self.array[index] = self.array[index], self.array[right]
|
||||
# Ripeto la procedura sul figlio modificato
|
||||
self._heapify_children(left)
|
||||
except IndexError:
|
||||
# La foglia non ha figli: ho finito!
|
||||
return
|
||||
|
||||
def pop(self):
|
||||
"""Restituisce la chiave con il valore minimo, e la elimina.
|
||||
|
||||
Costo:
|
||||
O(log n)"""
|
||||
# Mi salvo il valore della radice
|
||||
value = self.array[0]
|
||||
# Sostituisco la radice con l'ultima foglia a destra
|
||||
self.array[0], self.array[self.next_value] = self.array[self.next_value], self.array[0]
|
||||
### Non bisognerebbe eliminare la foglia...?
|
||||
# Riordino l'heap
|
||||
self._heapify_children(0)
|
||||
return value
|
||||
|
||||
@staticmethod
|
||||
def from_list(l):
|
||||
"""Crea un heap da una lista.
|
||||
|
||||
Costo:
|
||||
O(n log n), ma si può abbassare"""
|
||||
heap = Heap(len(l)))
|
||||
heap.array = Array.from_list(l) # Pseudocodice
|
||||
heap.next_value = len(l)
|
||||
# Cominciamo a riordinare l'heap dalla fine, in modo che rispetti le proprietà
|
||||
for index in range(heap.next_value, 0, -1):
|
||||
heap._heapify_children(index)
|
||||
```
|
||||
|
||||
## Visualizzazione
|
||||
|
||||
[visualgo.net](https://visualgo.net/en/heap)
|
||||
57
public/materials/year1/algoritmi/20_CodaConPriorità.md
Normal file
57
public/materials/year1/algoritmi/20_CodaConPriorità.md
Normal file
|
|
@ -0,0 +1,57 @@
|
|||
# Coda con priorità
|
||||
|
||||
La _coda con priorità_ è una struttura dati dal funzionamento molto simile a quello di una coda, ma invece che restituire il primo elemento inserito, essa restituisce l'**elemento con il valore di priorità minore**.
|
||||
|
||||
## Proprietà
|
||||
|
||||
- Ogni elemento è una coppia costituita da **valore** e **priorità** (un numero intero).
|
||||
- Nuovi elementi possono essere aggiunti solo tramite il **metodo `insert()`**
|
||||
- Gli elementi possono essere estratti solo tramite il **metodo `pop()`**
|
||||
- Verranno restituiti i valori inseriti secondo la strategia **Lower Priority** (l'elemento con la priorità minore sarà il primo ad essere restituito).
|
||||
- E' possibile diminuire la priorità di un elemento (e quindi anticipare la sua estrazione)
|
||||
|
||||
## Metodi
|
||||
|
||||
```python
|
||||
class PriorityQueue:
|
||||
def __init__(self): ...
|
||||
def insert(self, new_elem: Element): ...
|
||||
def minimum(self) -> Element: ...
|
||||
def pop(self) -> Element: ...
|
||||
def decrease_priority_for(self, elem: Element, priority: int): ...
|
||||
```
|
||||
|
||||
## Implementazione con lista
|
||||
|
||||
E' possibile implementare la coda con priorità tramite una **lista**: l'inserimento di nuovi valori diventerà molto efficiente, ma tutte le altre operazioni saranno linearmente lente.
|
||||
|
||||
### Costo computazionale
|
||||
|
||||
- *insert()*: `O(1)`
|
||||
- *minimum()*: `O(n)`
|
||||
- *pop()*: `O(n)`
|
||||
- *decrease_priority_for()*: `O(n)`
|
||||
|
||||
## Implementazione con lista ordinata
|
||||
|
||||
Implementando la coda con priorità con una **lista ordinata** si avrà un costo di ordinamento elevato negli inserimenti e modifiche alla priorità, ma costi costanti nell'estrazione di un elemento.
|
||||
|
||||
### Costo computazionale
|
||||
|
||||
- *insert()*: `O(n)`
|
||||
- *minimum()*: `O(1)`
|
||||
- *pop()*: `O(1)`
|
||||
- *decrease_priority_for()*: `O(n)`
|
||||
|
||||
## Implementazione con heap
|
||||
|
||||
La **soluzione migliore** è quella di implementare la coda con priorità tramite un **heap**: tutti i costi saranno logaritmici, eccetto l'inserimento che sarà costante.
|
||||
|
||||
- `insert()` costa `O(1)`
|
||||
- `minimum()` costa `O(log n)`
|
||||
- `pop()` costa `O(log n)`
|
||||
- `decrease_priority_for()` costa `O(log n)`
|
||||
|
||||
## Approfondimenti
|
||||
|
||||
Esistono code con priorità che restituiscono **l'elemento con priorità maggiore**, invece che quello minore.
|
||||
17
public/materials/year1/algoritmi/20_HeapSort.md
Normal file
17
public/materials/year1/algoritmi/20_HeapSort.md
Normal file
|
|
@ -0,0 +1,17 @@
|
|||
# Heap sort
|
||||
|
||||
L'_heap sort_ è un algoritmo di ordinamento per confronto **iterativo**.
|
||||
|
||||
## Funzionamento
|
||||
|
||||
Per effettuare un heap sort, creiamo un **heap massimo** in cui inseriamo tutti i valori che vogliamo ordinare.
|
||||
|
||||
Una volta applicate le proprietà dell'heap, chiamiamo una versione particolare di `heap.pop()` che invece che rimuovere dall'array i valori estratti li posiziona nello spazio creatosi in fondo.
|
||||
|
||||
## Costo computazionale
|
||||
|
||||
| Categoria | Upper bound | Lower bound | Tight bound |
|
||||
|-----------|-------------|-------------|-------------|
|
||||
| Tempo | `O(n log n)` | `Ω(n log n)` | **`θ(n log n)`** |
|
||||
|
||||
|
||||
144
public/materials/year1/algoritmi/21_Grafo.md
Normal file
144
public/materials/year1/algoritmi/21_Grafo.md
Normal file
|
|
@ -0,0 +1,144 @@
|
|||
# Grafo
|
||||
|
||||
Un _grafo_ è una struttura dati che rappresenta elementi interconnessi tra loro.
|
||||
|
||||
Esistono due tipi di grafi: _orientati_ e _non orientati_.
|
||||
|
||||
Per semplicità, consideriamo i nostri nodi numerati da 1 a `n`.
|
||||
|
||||
## Proprietà
|
||||
|
||||
- Gli elementi sono rappresentati tramite _nodi_.
|
||||
- Il loro _grado_ è dato dal **numero degli archi** che vi incidono.
|
||||
- Se il grafo è orientato, hanno anche un _in-degree_ (**numero di archi entranti**) e un _out-degree_ (**numero di archi uscenti**).
|
||||
- Le connessioni tra elementi sono rappresentate tramite _archi_.
|
||||
- Un arco _incide_ esattamente su **due nodi**.
|
||||
- Se il grafo è orientato, sono _uscenti_ da uno dei due nodi ed _entranti_ nell'altro.
|
||||
- Sono matematicamente meno del **quadrato dei nodi**.
|
||||
|
||||
## Grafi particolari
|
||||
|
||||
### Catena
|
||||
|
||||
Una _catena_ è un **grafo non orientato** composto da una **sequenza di nodi** aventi un **grado massimo di 2** tutti collegati tra loro.
|
||||
|
||||
### Cammino
|
||||
|
||||
Un _cammino_ è un **grafo orientato** composto da una **sequenza di nodi** aventi un **in-degree** e un **out-degree** **massimo di 1**, collegati tra loro in modo che partendo dal primo e seguendo gli archi sia possibile arrivare all'ultimo.
|
||||
|
||||
### Cricca
|
||||
|
||||
Una _cricca_ è un grafo in cui **tutti i nodi sono collegati tra loro**.
|
||||
|
||||
Se il grafo è **non orientato**, la cricca ha `((n-1)n)/2` archi.
|
||||
|
||||
Se il grafo è **orientato**, ha per ogni coppia un arco in entrambe le direzioni, quindi ha `(n-1)n` archi.
|
||||
|
||||
### Direct Acyclic Graph
|
||||
|
||||
Un _DAG_ è un grafo diretto che non contiene nessun ciclo.
|
||||
|
||||
Su di esso possiamo effettuare un ordinamento, detto _linearizzazione_, tra i nodi: otteniamo l'_ordine topologico_.
|
||||
|
||||
I primi elementi dei DAG sono detti _Source_ (_Sorgente_), mentre gli ultimi sono detti _Sink_ (_Pozzo_).
|
||||
|
||||
#### Albero
|
||||
|
||||
Un **albero** può essere considerato un DAG con una **sorgente singola** e le **foglie come pozzi**.
|
||||
|
||||
### Grafo fortemente connesso
|
||||
|
||||
Un insieme di nodi `V` di un **grafo diretto** `G` si dice una _componente fortemente connessa_ se:
|
||||
|
||||
1. Per ogni coppia di nodi `∀ u, v ∈ V' : ∃ un cammino u->v in G'`
|
||||
2. Massimale (non può diventare più grande)
|
||||
|
||||
> Praticamente una componente fortemente connessa è un gruppo di nodi tra i quali si può viaggiare liberamente da e a qualsiasi nodo al suo interno.
|
||||
|
||||
Un grafo si dice _fortemente connesso_ se l'insieme `V` coincide con l'insieme dei nodi del grafo `G`.
|
||||
|
||||
> Se partendo da qualsiasi nodo di un grafo riesco ad arrivare a qualsiasi altro nodo, allora il grafo è fortemente connesso.
|
||||
|
||||
Inoltre, se creiamo un nuovo grafo, in cui **ogni nodo rappresenta una componente fortemente connessa** del nostro grafo iniziale, **otteniamo un DAG**, perchè tutti i cicli sono stati integrati nella componente.
|
||||
|
||||
### Trasposto di un grafo
|
||||
|
||||
Il _trasposto_ di un **grafo diretto** `G` è il grafo stesso con gli archi che però vanno nella **direzione opposta**.
|
||||
|
||||
### Grafo pesato
|
||||
|
||||
Un _grafo pesato_ è un particolare grafo che associa a ciascun arco un **costo** per attraversarlo.
|
||||
|
||||
#### Costi negativi
|
||||
|
||||
I costi possono anche essere negativi: rappresenteranno allora un **guadagno** ottenuto attraversando il nodo.
|
||||
|
||||
### Minimum spanning tree
|
||||
|
||||
Un _minimum spanning tree_ è il **sottoinsieme degli archi** di un **grafo non diretto** che **connettono tutti i nodi** con il **minor costo possibile**.
|
||||
|
||||
I MST hanno [molte proprietà](https://en.wikipedia.org/wiki/Minimum_spanning_tree#Properties); sono troppe da scrivere qui, e probabilmente non ci interesseranno nemmeno.
|
||||
|
||||
## Implementazione tramite matrice di adiacenza
|
||||
|
||||
Possiamo implementare un grafo creando una **matrice di `bool` di dimensione `n * n`** in cui le **caselle collegate sono vere** e le caselle non collegate sono false.
|
||||
|
||||
> Ad esempio, possiamo implementare un grafo non orientato in questo modo (`█` indica l'esistenza di un collegamento e ` ` indica la sua assenza):
|
||||
>
|
||||
> | |1|2|3|
|
||||
> |-|-|-|-|
|
||||
> |1|░|░|░|
|
||||
> |2|█|░|░|
|
||||
> |3|█| |░|
|
||||
>
|
||||
> Esistono gli archi `1-2` e `1-3`, ma non esiste un collegamento `2-3`.
|
||||
|
||||
> Un grafo orientato invece si può implementare così:
|
||||
>
|
||||
> | |1|2|3|
|
||||
> |-|-|-|-|
|
||||
> |1|░|█| |
|
||||
> |2|█|░| |
|
||||
> |3|█| |░|
|
||||
>
|
||||
> Esistono gli archi `1->2`, `2->1` e `3->1`, ma non ci sono collegamenti `2->3`, `1->3` e `3->2`.
|
||||
|
||||
### Costo computazionale
|
||||
|
||||
#### Tempo
|
||||
|
||||
Le matrici di adiacenza portano alla realizzazione di algoritmi molto veloci: verificare l'esistenza di un arco è in `O(1)`!
|
||||
|
||||
Abbiamo però penalità significative quando vogliamo effettuare operazioni sugli archi: ad esempio, trovare il trasposto di un grafo implementato con una matrice di adiacenza è in `O(nodi²)`.
|
||||
|
||||
#### Memoria
|
||||
|
||||
E' poco efficiente in quanto a memoria: l'upper bound è in `O(n^2)`.
|
||||
|
||||
## Implementazione tramite liste di adiacenza
|
||||
|
||||
Un'alternativa alla matrice di adiacenza è quella di creare un'**array di liste**, le quali contengono i **vicini di ciascun nodo**.
|
||||
|
||||
> |Posizione|Lista|
|
||||
> |-|-|
|
||||
> |1|[2, 3]|
|
||||
> |2|[]|
|
||||
> |3|[1]|
|
||||
>
|
||||
> Esistono gli archi `1->2`, `1->3`, e `3->1`, ma non esistono `2->1`, `2->3` e `3->2`.
|
||||
|
||||
### Costo computazionale
|
||||
|
||||
#### Tempo
|
||||
|
||||
Utilizzando le liste di adiacenza, il tempo richiesto per verificare l'esistenza di un arco sale a `O(max-out-degree)`.
|
||||
|
||||
E' efficace però quando il problema che vogliamo risolvere riguarda operazioni su archi: trovare la trasposta è in `O(archi)`.
|
||||
|
||||
#### Memoria
|
||||
|
||||
La memoria richiesta dalle liste di adiacenza è minore di quella delle matrici: l'upper bound è in `O(nodi + archi)`.
|
||||
|
||||
## Visualizzazione
|
||||
|
||||
[visualgo.net](https://visualgo.net/en/graphds)
|
||||
94
public/materials/year1/algoritmi/22_VisitareUnGrafo.md
Normal file
94
public/materials/year1/algoritmi/22_VisitareUnGrafo.md
Normal file
|
|
@ -0,0 +1,94 @@
|
|||
# Visitare un grafo
|
||||
|
||||
Come per gli alberi radicati, esistono due modi per visitare un grafo: _depth-first search_ e _breadth-first search_.
|
||||
|
||||
In entrambi i casi, non visito mai due volte lo stesso nodo, e come risultato ottengo **molteplici alberi**, il cui insieme viene detto _foresta di copertura_.
|
||||
|
||||
Se il grafo che vogliamo visitare è diretto, allora dobbiamo **considerare come vicini solo gli archi uscenti**
|
||||
|
||||
## Depth-first search
|
||||
|
||||
La DFS ci può risultare utile per **identificare le componenti connesse** di un grafo e **identificare eventuali cicli**.
|
||||
|
||||
### Funzionamento
|
||||
|
||||
Posso utilizzare la DFS per classificare gli archi di un grafo in quattro categorie:
|
||||
|
||||
- _Tree_, archi che ci fanno **scoprire un nuovo nodo**
|
||||
- _Forward_, archi che ci portano a un **discendente**
|
||||
- _Back_, archi che ci portano ad un **antenato**
|
||||
- _Cross_, archi che **connettono due sottoalberi** diversi
|
||||
|
||||
Usiamo due array inizializzati a 0 chiamati `pre` e `post`, grandi quanto il numero di archi del grafo, che ci indicano rispettivamente quando un nodo è stato scoperto e quando è terminata la visita.
|
||||
Inoltre, creiamo una variabile `clock` che avanza ad ogni evento.
|
||||
Alla scoperta di un nuovo nodo, mettiamo il valore attuale di `clock` all'interno di `pre[n]`.
|
||||
Alla fine della visita di un nodo invece mettiamo il valore di `clock` in `post[n]`.
|
||||
|
||||
**Durante la visita**, gli archi avranno i seguenti valori:
|
||||
- _Tree_: `pre[dst] == 0`
|
||||
- _Forward_: `pre[src] < pre[dst] && post[dst] > 0`
|
||||
- _Back_: `pre[dst] < pre[src] && post[dst] == 0`
|
||||
- _Cross_: Tutti gli altri (`post[dst] < pre[src]`)
|
||||
|
||||
**A fine visita**, gli archi avranno i seguenti valori:
|
||||
- _Tree_: `pre[dst] < pre[dst] < post[dst] < pre[src]`
|
||||
- _Forward_: `pre[dst] < pre[dst] < post[dst] < pre[src]`
|
||||
- _Back_: `pre[src] < pre[dst] < post[dst] < post[src]`
|
||||
- _Cross_: `pre[dst] < post[dst] < pre[src] < post[src]`
|
||||
|
||||
Se un **grafo non diretto** contiene degli **archi Back**, allora esso **conterrà un ciclo**.
|
||||
|
||||
#### DFS nel grafo trasposto
|
||||
|
||||
Se effettuo una DFS sul trasposto di un grafo, posso **scoprire i nodi che hanno un cammino verso l'origine**.
|
||||
|
||||
#### DFS nella componente fortemente connessa
|
||||
|
||||
Se effettuo una DFS in una componente fortemente connessa e nella sua trasposta, il **`post` della trasposta sarà sempre minore** del `post` della componente originale.
|
||||
|
||||
### Costo computazionale
|
||||
|
||||
| Categoria | Upper bound | Lower bound | Tight bound |
|
||||
|-----------|-------------|-------------|-------------|
|
||||
| Tempo | `O(nodi + archi)` | `Ω(nodi + archi)` | **`θ(nodi + archi)`** |
|
||||
| Memoria | `O(nodi)` | `Ω(nodi)` | **`θ(nodi)`** |
|
||||
|
||||
### Visualizzazione
|
||||
|
||||
[visualgo.net](https://visualgo.net/en/dfsbfs)
|
||||
|
||||
## Breadth-first search
|
||||
|
||||
La BFS ci può risultare utile per **trovare tutti i nodi a una certa distanza** da un'origine.
|
||||
|
||||
### Costo computazionale
|
||||
|
||||
| Categoria | Upper bound | Lower bound | Tight bound |
|
||||
|-----------|-------------|-------------|-------------|
|
||||
| Tempo | `O(nodi + archi)` | `Ω(nodi + archi)` | **`θ(nodi + archi)`** |
|
||||
| Memoria | `O(nodi + archi)` | `Ω(nodi + archi)` | **`θ(nodi + archi)`** |
|
||||
|
||||
### Pseudocodice
|
||||
|
||||
Come per gli alberi, la implementiamo in modo **iterativo**:
|
||||
|
||||
```python
|
||||
queue = [starting_node]
|
||||
parents = [None for node in graph.nodes]
|
||||
distance = [-1 for node in graph.nodes]
|
||||
|
||||
# TODO: controllami quando sei più sveglio
|
||||
|
||||
while queue:
|
||||
node, source, distance = queue.pop(0)
|
||||
parents[node.number] = source
|
||||
distance[node.number] = distance
|
||||
for neighbour in node.neighbours:
|
||||
queue.append((neighbour, node, distance+1))
|
||||
```
|
||||
|
||||
> Nella coda, la distanza massima tra un nodo e l'altro è 1.
|
||||
|
||||
### Visualizzazione
|
||||
|
||||
[visualgo.net](https://visualgo.net/en/dfsbfs)
|
||||
22
public/materials/year1/algoritmi/23_AlgoritmiGreedy.md
Normal file
22
public/materials/year1/algoritmi/23_AlgoritmiGreedy.md
Normal file
|
|
@ -0,0 +1,22 @@
|
|||
# Algoritmi greedy
|
||||
|
||||
Un modo per risolvere problemi algoritmici può essere usare una **tecnica** _greedy_.
|
||||
|
||||
Le tecniche greedy consistono nel effettuare tanti piccoli passi, ed effettuare una **scelta** in base ai dati **locali al passo attuale**.
|
||||
|
||||
> Scegli il numero di monete più piccole possibili per comporre €1.12.
|
||||
>
|
||||
> L'algoritmo cerca di scegliere sempre la moneta più grande possibile compatibile con il prezzo in quel momento, quindi:
|
||||
> | Moneta scelta | Rimanente |
|
||||
> |---------------|-----------|
|
||||
> | € 1.00 | € 0.12 |
|
||||
> | € 0.10 | € 0.02 |
|
||||
> | € 0.02 | € 0.00 |
|
||||
|
||||
## Esempi
|
||||
|
||||
Sono algoritmi greedy:
|
||||
|
||||
- L'_Algoritmo di Dijkstra_
|
||||
- L'_Algoritmo di Kruskal_
|
||||
- L'_Algoritmo di Prim_
|
||||
21
public/materials/year1/algoritmi/24_PercorsoPiùBreve.md
Normal file
21
public/materials/year1/algoritmi/24_PercorsoPiùBreve.md
Normal file
|
|
@ -0,0 +1,21 @@
|
|||
# Percorso più breve
|
||||
|
||||
Trovare il _percorso più breve_ (o _cammino minimo_) tra due nodi di un **grafo pesato** è un problema frequente nell'informatica; per questo, sono stati sviluppati [numerosi algoritmi](https://en.wikipedia.org/wiki/Shortest_path_problem) per risolverlo.
|
||||
|
||||
> Ad esempio, il pathfinding dei nemici nei videogiochi, oppure Google Maps!
|
||||
|
||||
## Percorso più breve da una sorgente singola
|
||||
|
||||
Una sottocategoria del problema del percorso più breve è il caso in cui ci interessa sapere i percorsi più brevi che **partono da uno specifico nodo del grafo**: è detto problema del _percorso più breve da una sorgente singola_, o _single-source shortest path_.
|
||||
|
||||
Si può notare che se il grafo contiene **costi negativi** allora è possibile che il percorso più breve non esista, in quanto diventa possibile la comparsa di **cicli di costo infinitamente negativo**.
|
||||
|
||||
Possiamo notare che, se il percorso più breve tra `A` e `D` è `A-B-C-D`, allora il cammino minimo tra `B` e `D` passerà obbligatoriamente per `C` (`B-C-D`).
|
||||
Diremo più avanti che il percorso più breve ha una **sottostruttura ottimale**.
|
||||
|
||||
### Esempi
|
||||
|
||||
Alcuni algoritmi che trovano il percorso più breve sono:
|
||||
- L'_Algoritmo di Dijkstra_
|
||||
- L'_Algoritmo di Bellman-Ford_
|
||||
- La [_ricerca A*_](https://en.wikipedia.org/wiki/A*_search_algorithm)
|
||||
68
public/materials/year1/algoritmi/25_AlgoritmoDiDijkstra.md
Normal file
68
public/materials/year1/algoritmi/25_AlgoritmoDiDijkstra.md
Normal file
|
|
@ -0,0 +1,68 @@
|
|||
# Algoritmo di Dijkstra
|
||||
|
||||
L'_Algoritmo di [Dijkstra](https://upload.wikimedia.org/wikipedia/commons/8/85/Dijkstra.ogg)_ è un algoritmo che risolve il problema del **percorso più breve da una sorgente singola** per grafi con pesi **reali positivi** `\mathbb{R}^+`.
|
||||
|
||||
L'algoritmo trova tutti i percorsi più brevi per raggiungere qualsiasi nodo del grafo partendo da un dato nodo, assieme al costo richiesto per farlo.
|
||||
|
||||
## Funzionamento
|
||||
|
||||
1. Separiamo tutti i nodi del grafo in due gruppi: **visitati** e **non visitati**.
|
||||
- Tutti i nodi partono da **non visitati**.
|
||||
2. Per ogni nodo, manteniamo un valore "**costo richiesto per raggiungerlo**", che verrà cambiato man mano che l'algoritmo avanza.
|
||||
- Il costo di partenza è `+∞`.
|
||||
- Il costo sarà **definitivo per i nodi visitati**, e **provvisorio per i non visitati**.
|
||||
3. Creiamo un insieme detto _frontiera_ che conterrà tutti i **nodi non visitati adiacenti** a quelli visitati.
|
||||
4. Prendiamo il nodo iniziale, che avrà un **costo di `0`**, e definiamolo il nodo _attuale_.
|
||||
5. Finchè ci sono dei nodi non sono stati visitati, ripetiamo il seguente ciclo:
|
||||
1. Aggiungiamo i nodi adiacenti al nodo attuale alla frontiera.
|
||||
- Il costo per raggiungerli sarà il **costo per il nodo attuale sommato al costo dell'arco** che li connette al nodo attuale.
|
||||
Se questo **costo** risulta essere **minore del costo provvisorio** precedente, esso **diventerà il nuovo costo**.
|
||||
- Questa operazione è detta _rilassamento dell'arco_.
|
||||
2. Facciamo diventare **visitato** il nodo attuale.
|
||||
- Il percorso che abbiamo fatto per raggiungerlo è obbligatoriamente il più breve.
|
||||
3. Il prossimo nodo attuale sarà il nodo di frontiera con un costo più basso.
|
||||
- Per questo, è possibile definire l'algoritmo di Dijkstra come un **algoritmo greedy**.
|
||||
|
||||
### Non funziona se...
|
||||
|
||||
L'algoritmo smette di funzionare nel caso in cui siano presenti **costi negativi** e il grafo non sia **aciclico**, in quanto non saremmo mai in grado di rendere visitato un nodo.
|
||||
|
||||
## Costo computazionale
|
||||
|
||||
| Categoria | Upper bound |
|
||||
|-----------|-------------|
|
||||
| Tempo | `O(nodi + archi) log nodi)` |
|
||||
|
||||
### Scomposizione
|
||||
|
||||
- Inizializzazione: `O(nodi)`
|
||||
- Creazione coda priorità: `O(nodi log nodi)`
|
||||
- Ciclo: `O((nodi + archi) log nodi)`
|
||||
|
||||
## Pseudocodice
|
||||
|
||||
```python
|
||||
import math
|
||||
|
||||
class Info:
|
||||
def __init__(self, distance=math.inf, previous=None):
|
||||
self.distance = distance
|
||||
self.previous = previous
|
||||
|
||||
def dijkstra(graph, start):
|
||||
data = [Info() for node in graph.nodes]
|
||||
queue = PriorityQueue([start])
|
||||
while queue:
|
||||
node = queue.pop()
|
||||
for arc in node.connections:
|
||||
other = arc.other(node)
|
||||
if data[node.number].distance + arc.cost < data[other].distance:
|
||||
data[other].distance = data[node.number].distance + arc.cost
|
||||
queue.decrease_priority_for(other, data[other].distance)
|
||||
data[v].previous = node
|
||||
return data
|
||||
```
|
||||
|
||||
## Visualizzazione
|
||||
|
||||
[Visualgo](https://visualgo.net/en/sssp)
|
||||
|
|
@ -0,0 +1,25 @@
|
|||
# Algoritmo di Bellman-Ford
|
||||
|
||||
L'_Algoritmo di Bellman-Ford_ è un algoritmo che, come l'Algoritmo di Dijkstra, risolve il problema del **percorso più breve da una sorgente singola**, però, a differenza da quest'ultimo, l'Algoritmo di Bellman-Ford accetta in input anche grafi con pesi **reali** `\mathbb{R}` (sia positivi, sia negativi).
|
||||
|
||||
## Funzionamento
|
||||
|
||||
L'approccio dell'algoritmo è simile a quello di Dijkstra: entrambi usano il **rilassamento** degli archi per ottenere un costo provvisorio per il raggiungimento di un nodo, ma invece che rilassare solo l'arco con costo inferiore, questo algoritmo **rilassa tutti gli archi** ripetutamente, eliminando la frontiera e il problema dei nodi negativi.
|
||||
|
||||
L'operazione di rilassamento è ripetuta `nodi - 1` volte, ovvero la **lunghezza massima** di un cammino aciclico all'interno di un grafo.
|
||||
|
||||
Possiamo individuare dopo i rilassamenti se è presente un nodo con un **ciclo negativo**: ci basta controllare se esiste un arco che connette due nodi con una distanza incompatibile: se `a.distanza + arco.costo < b.distanza`, allora è presente un ciclo negativo.
|
||||
|
||||
## Costo computazionale
|
||||
|
||||
| Categoria | Upper bound |
|
||||
|-----------|-------------|
|
||||
| Tempo | `O(nodi * archi)` |
|
||||
|
||||
## Pseudocodice
|
||||
|
||||
> TODO
|
||||
|
||||
## Visualizzazione
|
||||
|
||||
[Visualgo](https://visualgo.net/en/sssp)
|
||||
58
public/materials/year1/algoritmi/27_DisjointSet.md
Normal file
58
public/materials/year1/algoritmi/27_DisjointSet.md
Normal file
|
|
@ -0,0 +1,58 @@
|
|||
# Disjoint set
|
||||
|
||||
Il _disjoint set_ è una struttura dati che rappresenta elementi di un insieme raggruppati in **sottoinsiemi disgiunti**.
|
||||
|
||||
## Metodi
|
||||
|
||||
```python
|
||||
class DisjointNode:
|
||||
def __init__(self): ...
|
||||
def find_set(self): "Trova il rappresentante dell'elemento."
|
||||
def union(self, other): "Unisce i sottoinsiemi che contengono questo nodo e `other`."
|
||||
```
|
||||
|
||||
## Implementazione tramite array
|
||||
|
||||
Possiamo implementare il disjoint set con due array: uno per l'**indice del rappresentante** e uno per il **rango dell'insieme**.
|
||||
|
||||
Un singoletto avrà **sè stesso come rappresentante** e **rango `0`**.
|
||||
|
||||
### Costo computazionale
|
||||
|
||||
- *create_set()*: `O(1)`
|
||||
- *find_set()*: `O(h)`
|
||||
- *union()*: `O(h)`
|
||||
|
||||
### Pseudocodice
|
||||
|
||||
```python
|
||||
class DisjointNode:
|
||||
def __init__(self):
|
||||
self.parent = self
|
||||
self.rank = 0
|
||||
|
||||
def find_set(self):
|
||||
element = self
|
||||
while self.parent != element:
|
||||
element = self.parent
|
||||
return element
|
||||
|
||||
def union(self, other):
|
||||
repres_self = self.find_set()
|
||||
repres_other = other.find_set()
|
||||
if repres_self == repres_other:
|
||||
return
|
||||
if repres_self.rank < repres_other.rank:
|
||||
repres_greater = repres_other
|
||||
repres_lesser = repres_self
|
||||
else:
|
||||
repres_greater = repres_self
|
||||
repres_lesser = repres_other
|
||||
repres_lesser.parent = repres_greater
|
||||
if repres_greater.rank == repres_lesser.rank:
|
||||
repres_greater.rank += 1
|
||||
```
|
||||
|
||||
### Visualizzazione
|
||||
|
||||
[cs.usfca.edu](https://www.cs.usfca.edu/~galles/JavascriptVisual/DisjointSets.html)
|
||||
12
public/materials/year1/algoritmi/28_TrovareIlMST.md
Normal file
12
public/materials/year1/algoritmi/28_TrovareIlMST.md
Normal file
|
|
@ -0,0 +1,12 @@
|
|||
Trovare il minimum spanning tree
|
||||
|
||||
Un altro problema ricorrente riguardante i grafi è trovare il _minimum spanning tree_ di un dato grafo non diretto.
|
||||
|
||||
> E' utile per trovare il modo più efficiente per connettere le cose: ad esempio, per decidere la struttura di una rete internet!
|
||||
|
||||
## Esempi
|
||||
|
||||
Gli algoritmi principali che risolvono il problema sono due, ed entrambi sono **algoritmi greedy**:
|
||||
|
||||
- L'_Algoritmo di Kruskal_
|
||||
- L'_Algoritmo di Prim_
|
||||
40
public/materials/year1/algoritmi/29_AlgoritmoDiKruskal.md
Normal file
40
public/materials/year1/algoritmi/29_AlgoritmoDiKruskal.md
Normal file
|
|
@ -0,0 +1,40 @@
|
|||
# Algoritmo di Kruskal
|
||||
|
||||
L'_Algoritmo di Kruskal_ è un algoritmo **greedy** che **trova il minimum spanning tree** di un grafo.
|
||||
|
||||
## Funzionamento
|
||||
|
||||
1. Ripetiamo questa procedura finchè tutti i nodi non sono connessi:
|
||||
1. Prendiamo ad ogni passo **l'arco meno costoso** del grafo non ancora aggiunto all'insieme.
|
||||
2. Assicuriamoci che **non si creino cicli**: se non se ne verrebbero a creare, possiamo **aggiungere l'arco all'insieme**.
|
||||
- Gli archi devono quindi connettere nodi in **componenti connesse diverse**.
|
||||
- Possiamo rappresentare le componenti connesse con un **Disjoint Set**.
|
||||
|
||||
## Costo computazionale
|
||||
|
||||
| Categoria | Upper bound |
|
||||
|-----------|-------------|
|
||||
| Tempo | `O(archi²)` |
|
||||
|
||||
### Scomposizione
|
||||
|
||||
- DisjointSet.__init__(): `O(archi)`
|
||||
- Per ogni ciclo: `O(archi²)`
|
||||
- DisjointSet.find_set(): `O(1)`
|
||||
- DisjointSet.union(): `O(archi)`
|
||||
|
||||
## Pseudocodice
|
||||
|
||||
```python
|
||||
def minimum_spanning_tree_kruskal(graph):
|
||||
ds = DisjointSet()
|
||||
for node in graph.nodes:
|
||||
ds.create_set(node)
|
||||
arcs = []
|
||||
sorted_arcs = sorted(graph.arcs, key=lambda arc: arc.cost)
|
||||
for arc in sorted_arcs:
|
||||
if ds.find_set(node.start) != ds.find_set(node.end):
|
||||
arcs.append(arc)
|
||||
ds.union(node.start, node.end)
|
||||
return arcs
|
||||
```
|
||||
49
public/materials/year1/algoritmi/29_AlgoritmoDiPrim.md
Normal file
49
public/materials/year1/algoritmi/29_AlgoritmoDiPrim.md
Normal file
|
|
@ -0,0 +1,49 @@
|
|||
# Algoritmo di Prim
|
||||
|
||||
L'_Algoritmo di Prim_ è un altro algoritmo **greedy** che **trova il minimum spanning tree** di un grafo.
|
||||
|
||||
## Funzionamento
|
||||
|
||||
Creo una **coda con priorità** in cui inserisco tutti gli archi visibili dal mio albero, in cui la chiave è il **costo dell'arco**.
|
||||
|
||||
Per trovare l'arco con costo più piccolo posso **estrarre un arco** dalla coda: la priorità ci garantisce che esso è l'**arco meno costoso**.
|
||||
|
||||
Aggiungo allora un nuovo nodo all'albero, e con esso, **aggiungo alla coda** tutti gli **archi che scoprono un nuovo nodo**.
|
||||
|
||||
## Costo computazionale
|
||||
|
||||
| Categoria | Upper bound |
|
||||
|-----------|-------------|
|
||||
| Tempo | `O(archi + nodi log nodi)` |
|
||||
|
||||
## Pseudocodice
|
||||
|
||||
```python
|
||||
import math
|
||||
|
||||
def minimum_spanning_tree_prim(graph, cost_array, start_node):
|
||||
# E' un Array di bool: se l'indice corrispondente al nodo è uguale a true, vuol dire che il (nodo è contenuto nell'albero.
|
||||
contains = [False for _ in range(len(graph))]
|
||||
# Contiene il precedente di ogni nodo
|
||||
prev = [None for _ in range(len(graph))]
|
||||
# Contiene il costo per arrivare a quel nodo
|
||||
cost = [math.inf for _ in range(len(graph))]
|
||||
# Creo la priority queue
|
||||
pq = PriorityQueue(graph.arcs, key=lambda arc: arc.cost)
|
||||
# Parto dal nodo `start_index`
|
||||
# Il costo dell'origine è 0.
|
||||
cost[start_node.index] = 0
|
||||
contains[start_node.index] = True
|
||||
|
||||
while not pq.is_empty():
|
||||
new_node = pq.pop()
|
||||
contains[new_node.index] = True
|
||||
for arc in new_node.connections:
|
||||
other_node = arc.other(new_node)
|
||||
if not contains[other_node.index] and cost[other_node.index] > arc.cost:
|
||||
cost[other_node.index] = arc.cost
|
||||
prev[other_node.index] = new_node
|
||||
pq.decrease_priority_for(other_node, arc.cost)
|
||||
# L'array di prev rappresenta un albero.
|
||||
return prev
|
||||
```_
|
||||
51
public/materials/year1/algoritmi/30_Compressione.md
Normal file
51
public/materials/year1/algoritmi/30_Compressione.md
Normal file
|
|
@ -0,0 +1,51 @@
|
|||
# Compressione
|
||||
|
||||
_Comprimere_ un file significa **ridurne le dimensioni** senza modificarne il significato.
|
||||
|
||||
## Categorie
|
||||
|
||||
### Compressione lossless
|
||||
|
||||
Nella _compressione lossless_, i dati possono essere decompressi riottenendo una copia identica dell'originale.
|
||||
|
||||
> Immaginiamo un file che contiene solo le lettere `a, b, c, d, e, f`.
|
||||
>
|
||||
> Le lettere compaiono con questa frequenza:
|
||||
> |a|b|c|d|e|f|
|
||||
> |45%|13%|12%|16%|9%|5%|
|
||||
>
|
||||
> Possiamo codificare le lettere nel seguente modo:
|
||||
> |a|b|c|d|e|f|
|
||||
> |`0b0`|`0b100`|`0b101`|`0b111`|`0b1100`|`0b1101`|
|
||||
>
|
||||
> Scrivere `abacadae` richiederebbe 64 bits con la codifica ASCII estesa, ma in questo modo riusciamo a scriverlo con soli 17 bits!
|
||||
|
||||
Le codifiche di un file compresso devono rispettare la proprietà del _Codice a prefisso_, che dice che **nessun codice deve essere il prefisso di un altro codice**; altrimenti, si avrebbero ambiguità nella decodifica.
|
||||
|
||||
> a = `1`
|
||||
> b = `11`
|
||||
>
|
||||
> `111` è `ab`, `ba` oppure `aaa`?
|
||||
|
||||
Creiamo allora un _albero di decodifica_: un **albero binario** che, leggendo uno ad uno i bit codificati, ci permette di arrivare al **valore del codice presente sulle foglie** dell'albero.
|
||||
|
||||
Gli alberi di decodifica sono sempre **completi**.
|
||||
|
||||
> Un albero di decodifica incompleto sarebbe non ottimizzato!
|
||||
|
||||
#### Esempi
|
||||
|
||||
- .png
|
||||
- .flac
|
||||
- .zip
|
||||
- ...
|
||||
|
||||
### Compressione lossy
|
||||
|
||||
Nella _compressione lossy_, alcuni dati [solitamente](http://needsmorejpeg.com/) irrilevanti vengono perduti: non si può, dunque, ricostruire l'originale.
|
||||
|
||||
#### Esempi
|
||||
|
||||
- .jpeg
|
||||
- .mp3
|
||||
- ...
|
||||
14
public/materials/year1/algoritmi/31_AlgoritmoDiHuffman.md
Normal file
14
public/materials/year1/algoritmi/31_AlgoritmoDiHuffman.md
Normal file
|
|
@ -0,0 +1,14 @@
|
|||
# Algoritmo di Huffman
|
||||
|
||||
L'_Algoritmo di Huffman_ è un **algoritmo greedy** per la **costruzione di un albero di decodifica**.
|
||||
|
||||
## Funzionamento
|
||||
|
||||
1. Costruisco **un albero** (con un solo nodo) **per ogni elemento dell'alfabeto**.
|
||||
2. Associo ad **ogni albero la frequenza dell'elemento** da cui è stato creato, per poi inserire tutti gli elementi in una coda con priorità.
|
||||
3. Finchè non ho **un albero solo**:
|
||||
1. Estraggo dalla coda i **due alberi con frequenza minore**.
|
||||
2. **Li rendo fratelli**, creando un nuovo nodo in cui sono uno figlio destro e uno figlio sinistro.
|
||||
3. Associo al nuovo nodo la **somma delle frequenze dei due alberi**, e inserisco il nuovo albero nella coda.
|
||||
|
||||
> È molto raro che venga un albero "dritto"; se succede, probabilmente c'è qualcosa che non va.
|
||||
49
public/materials/year1/algoritmi/32_Dizionari.md
Normal file
49
public/materials/year1/algoritmi/32_Dizionari.md
Normal file
|
|
@ -0,0 +1,49 @@
|
|||
# Dizionario
|
||||
|
||||
Un _dizionario_ è una struttura dati che **associa dei valori a delle chiavi**.
|
||||
|
||||
## Proprietà
|
||||
|
||||
- Ogni elemento del dizionario è un **valore** che è stato **associato a una chiave**.
|
||||
- Possiamo aggiungere nuovi elementi con il **metodo `add(chiave, valore)`**.
|
||||
- Posiamo estrarre elementi con il **metodo `get(chiave)`**, che restituirà il valore associato a `chiave`.
|
||||
- E' possibile rimuovere elementi con il **metodo `delete(chiave)`**.
|
||||
- Due elementi con **chiavi diverse** non devono **mai restituire lo stesso valore**.
|
||||
|
||||
## Metodi
|
||||
|
||||
Beh... Non ha molto senso in questo caso...
|
||||
|
||||
```python
|
||||
dict()
|
||||
```
|
||||
|
||||
## Implementazione con tabella hash
|
||||
|
||||
Una _tabella hash_ è un'array di coppie **chiave-valore**, che formano l'insieme _universo_.
|
||||
|
||||
Per determinare l'**indice dell'array** in cui inserire una coppia, usiamo una [funzione _hash_](https://it.wikipedia.org/wiki/Hash#Algoritmo_di_hash) sulla chiave, che restituirà **numeri da `0` a `len(hash_table)`**.
|
||||
|
||||
### Risoluzione collisioni
|
||||
|
||||
Potrebbe capitare però che **due chiavi diverse abbiano lo stesso indice**. Dobbiamo allora usare un metodo di _risoluzione collisioni_, che mi permetta di distinguere tra chiavi diverse.
|
||||
|
||||
#### Lista di trabocco
|
||||
|
||||
Possiamo salvare nell'array **liste di coppie** chiave-valore; in caso di collisione, **aggiungo un nuovo elemento alla lista**.
|
||||
|
||||
In media, ciascuna di queste liste conterrà `elementi_inseriti / dimensione_tabella` elementi.
|
||||
|
||||
#### Indirizzamento aperto
|
||||
|
||||
Possiamo decidere di mettere le coppie che non trovano posto nel loro indice in **un altro indirizzo vuoto** dell'array.
|
||||
|
||||
Ci sono diversi modi in cui decidere il nuovo indirizzo, ognuno con vantaggi e svantaggi: si può scegliere quello successivo, oppure il primo vuoto dell'array, oppure un indirizzo casuale.
|
||||
|
||||
> Python, nei `dict`, usa indirizzamento aperto pseudorandom.
|
||||
|
||||
### Costo computazionale
|
||||
|
||||
- Aggiungere una chiave: `O(n)`
|
||||
- Trovare una chiave: `O(n)`
|
||||
- Eliminare una chiave: `O(n)`
|
||||
|
|
@ -0,0 +1,48 @@
|
|||
# Programmazione dinamica
|
||||
|
||||
La _programmazione dinamica_ è una **tecnica** di programmazione che prevede l'**estensione di una soluzione ottima precedente**.
|
||||
|
||||
Tutti i problemi in cui si può applicare si possono risolvere anche con la **ricorsione**, ma a differenza della ricorsione, questa tecnica riesce ad evitare di ricalcolare la soluzione per ogni chiamata ricorsiva, ottenendo quindi tempi molto migliori.
|
||||
|
||||
Si può applicare solo se un problema ha una **sottostruttura ottimale**, ovvero se la soluzione ottima di un sottoproblema è inclusa nella soluzione ottima del problema.
|
||||
|
||||
## Esempi
|
||||
|
||||
- _Problema dello zaino_
|
||||
- ...
|
||||
|
||||
> Il cammino minimo per raggiungere un nodo in un DAG è dato da `arco.costo + arco.primo_nodo.costo_cammino_minimo()`.
|
||||
>
|
||||
> ```python
|
||||
> def SPD_PD(graph, start):
|
||||
> distance = [float(inf) for node in graph.nodes]:
|
||||
> distance[start] = 0
|
||||
> # I nodi devono essere in ordine di linearizzazione
|
||||
> for node in graph.nodes:
|
||||
> distance[node] = min([(arc.cost + distance[arc.other(node)] for arc in node.connections])
|
||||
> ```
|
||||
|
||||
> Ho una sequenza di interi da `a_1` a `a_n`. Voglio trovare la sottosequenza crescente più lunga.
|
||||
>
|
||||
> 5 2 3 4 7 3 6 3 1 6
|
||||
>
|
||||
> Trovo tutte le sequenze lunghe 1, e le rendo nodi di un grafo diretto.
|
||||
>
|
||||
> Da ogni nodo, creo una connessione verso i suoi maggiori.
|
||||
>
|
||||
> Infine, cerco i cammini massimi del grafo.
|
||||
>
|
||||
> Essi saranno la soluzione del problema.
|
||||
|
||||
> Trova la lunghezza della sottosequenza più lunga che termina con `j`.
|
||||
>
|
||||
> `L[j]` = lunghezza della sottosequenza più lunga che termina in `j`
|
||||
>
|
||||
> ```python
|
||||
> L[j] = max([1 + L[node] for arc in node.connections)]
|
||||
> ```
|
||||
>
|
||||
> Esempio:
|
||||
> ```python
|
||||
> L[9] = max([1+L[8], 1+L[3], 1+L[6]])
|
||||
> ```
|
||||
85
public/materials/year1/algoritmi/34_ProblemaDelloZaino.md
Normal file
85
public/materials/year1/algoritmi/34_ProblemaDelloZaino.md
Normal file
|
|
@ -0,0 +1,85 @@
|
|||
# Problema dello zaino
|
||||
|
||||
Il problema dello zaino è un problema _pseudo-trattabile_: non abbiamo dimostrazioni di se sia trattabile o intrattabile.
|
||||
|
||||
## Descrizione
|
||||
|
||||
> Sei un ladro, e devi mettere **più refurtiva possibile** nello zaino per scappare.
|
||||
> Lo zaino può portare **al massimo `dim` kili**.
|
||||
>
|
||||
> **Quali** (e quanti) oggetti scegli?
|
||||
|
||||
| Input | Output |
|
||||
|-------|--------|
|
||||
| `dim`ensione_zaino, `n`umero_oggetti, `oggetto.peso`, `oggetto.valore` | `profitto_massimo` |
|
||||
|
||||
## Categorie
|
||||
|
||||
### Problema con ripetizione
|
||||
|
||||
Puoi prendere **tutte le copie che vuoi** di un oggetto.
|
||||
|
||||
#### Soluzione
|
||||
|
||||
`K(dim)` è il valore massimo ottenibile con uno zaino di capacità `dim`.
|
||||
|
||||
> Se `i` appartenesse alla soluzione ottima, allora `K(dim) = i.valore + K(dim - i.peso)`...
|
||||
|
||||
Possiamo dire che `K(dim) = max(i.valore + K(dim - i.peso))`.
|
||||
|
||||
Inoltre, `K(0) = 0`.
|
||||
|
||||
Ci salviamo tutte le soluzioni da `K(0)` a `K(dim)`, e le usiamo per calcolare il massimo in seguito.
|
||||
|
||||
Calcolare `K(dim)` avrà allora un costo di `O(n * dim)`:
|
||||
- `n`, perchè trovare il massimo è un'operazione lineare
|
||||
- `dim`, perchè `dim` sono tutti i casi tra i quali devo andare a provare
|
||||
|
||||
Il costo computazionale, allora, è in `O(n * dim)`.
|
||||
|
||||
Però, il **tempo richiesto** dal nostro algoritmo dipende non dalla lunghezza dell'input, bensì dal **valore numerico** di `dim`, che corrisponde alla dimensione dell'array delle soluzioni.
|
||||
Allora, si dice che l'algoritmo è in **tempo _pseudo-polinomiale_**.
|
||||
|
||||
### Problema senza ripetizione
|
||||
|
||||
Si può prendere **ogni oggetto una volta sola**.
|
||||
|
||||
#### Soluzione _bruteforce_
|
||||
|
||||
Scelgo se prendere o no l'item 1.
|
||||
|
||||
Si creano due percorsi:
|
||||
- Non prendo l'oggetto: `valore = 0, peso = 0`
|
||||
- Prendo l'oggetto: `valore = oggetto.valore, peso = oggetto.peso`
|
||||
|
||||
Continuo a creare percorsi, creando una specie di albero binario.
|
||||
|
||||
Se a un certo punto vedo che `valore = x, peso = K` e `valore < x, peso = K`, allora posso escludere automaticamente tutto il sottoalbero destro, perchè non può essere migliore del sinistro: allora, sarò riuscito a ridurre il numero dei casi rispetto alla ricorsione.
|
||||
|
||||
### Problema in due variabili
|
||||
|
||||
`K(j, w)` = massimo valore ottenibile con uno zaino di capacità `w` scegliendo gli item da `1` a `j`.
|
||||
|
||||
Non possiamo più applicare la soluzione bruteforce, perchè abbiamo due variabili, `j` e `w`.
|
||||
|
||||
Allora, prendo l'elemento `j`. Esso può essere o non essere nella soluzione: mi calcolo entrambe le alternative, e mi tengo l'alternativa dal valore più alto.
|
||||
|
||||
Se `j` non è nella soluzione, il risultato diventerà `K(j-1, w)`; se invece è nella soluzione, il risultato sarà `j.valore + K(j-1, w-j.peso)`.
|
||||
|
||||
In pratica, prendiamo
|
||||
|
||||
```latex
|
||||
K(j, w) = max
|
||||
\begin{cases}
|
||||
V_j + K(j-1, w-w_j)
|
||||
K(j-1, w)
|
||||
\end{cases}
|
||||
```
|
||||
|
||||
Costruisco allora una matrice con `j` su un asse e `w` sull'altro.
|
||||
Riempio le caselle con il valore di `K(j, w)`.
|
||||
Nella casella con `K(j, w)` avremo la soluzione ottima.
|
||||
|
||||
Il tempo necessario per riempire tutte le caselle è nuovamente `O(n * w)`, ancora **pseudopolinomiale**.
|
||||
|
||||
Per sapere che oggetti ho messo o no devo tenere traccia in qualche modo della catena del calcolo, usando, ad esempio, una pila.
|
||||
28
public/materials/year1/algoritmi/35_ProblemiIntrattabili.md
Normal file
28
public/materials/year1/algoritmi/35_ProblemiIntrattabili.md
Normal file
|
|
@ -0,0 +1,28 @@
|
|||
# Problemi intrattabili
|
||||
|
||||
## Problema di Set-Cover
|
||||
|
||||
### Input
|
||||
|
||||
`U`niverso di `e`lementi
|
||||
|
||||
`S`ottoinsieme di `s`ottoinsiemi di elementi di `U`
|
||||
|
||||
### Output
|
||||
|
||||
Il minimo `S'`ottoinsieme di `s`ottoinsiemi che copra completamente `U`.
|
||||
|
||||
### Soluzione in `O(n^d)`
|
||||
|
||||
Non c'è.
|
||||
|
||||
### Non-soluzione alternativa
|
||||
|
||||
Faccio una scelta greedy, ma non posso dimostrare in alcun modo che la soluzione ottenuta sia quella ottima.
|
||||
Infatti, l'algoritmo non dà sempre la soluzione ottima, ma dà una soluzione accettabile in tempo polinomiale.
|
||||
|
||||
Seleziono sempre il sottoinsieme che copre più elementi mancanti possibili.
|
||||
|
||||
#### Costo computazionale
|
||||
|
||||
`Costo greedy <= log(numero_elementi) * Costo ottimo`
|
||||
Loading…
Add table
Reference in a new issue